近几年来,人工智能技术的迅猛进步正在深刻改变各行各业的运作方式,特别是在内容创作领域,AI的应用已逐渐普及。作为全球最大的职场社交平台,LinkedIn也宣布将利用用户数据来训练其内容创作AI模型,以提升平台服务质量和用户体验。然而,这一举措引发了广泛关注与讨论,许多用户担心自己的数据会被滥用或隐私受到侵犯。本文将全面解读LinkedIn这一政策变化,讲述用户如何进行选择退出操作,并深入分析此举对于用户和整个职场生态的潜在影响。 LinkedIn公布的这一政策指出,自2025年11月3日起,LinkedIn将使用来自用户所在区域的数据信息训练其内容生成AI,目的是帮助用户更好地创作个人资料更新、职业信息及帖子内容,并辅助招聘者更精准地找到合适人才。具体来说,平台将利用公开的个人资料和帖子数据,而不包括私人消息内容。
这种数据驱动的AI系统能够为用户提供更智能、更高效的内容建议,提升个人和企业的在线影响力。 尽管官方宣称用户可以在设置中随时选择不参与数据训练,但用户普遍反映相关设置入口存在登录阻塞问题,甚至怀疑该登录循环是平台为阻碍用户选择退出而设置的障碍。具体而言,部分用户通过邮件中的链接访问设置时,频繁遭遇需要重复登录且无法顺利到达终端选项页面的情况。这样的用户体验无疑加剧了公众对数据隐私保护以及平台诚信度的担忧。 在处理用户数据用于AI训练的问题上,不同地区的法规要求各有差异。欧盟个人数据保护条例(GDPR)对企业在收集和使用个人数据上设定了严格的规范,许多欧洲用户能够依照法规规定更方便地行使数据使用拒绝权。
相比之下,其他地区的用户,则可能面临更复杂的选择过程。对于LinkedIn这样跨国大型平台而言,如何平衡业务需求与用户隐私权成了一个急需解决的难题。 很多用户对此政策持谨慎甚至抵触态度。他们担忧自己的原创内容、观点和数据会被平台以无偿方式"剽窃",用于训练商业级AI模型,从而间接助力微软等大公司获利,而自己却得不到相应的回报。此外,也不乏用户担忧这种大规模的数据利用可能带来隐私泄露风险,尤其是对职业信息敏感的用户而言,控制内容传播范围尤为重要。 另一方面,也有部分用户认为,参与AI内容模型训练其实能提升个人在平台上的曝光率,因为未来的搜索引擎和推荐系统将更偏向于包含AI创作能力和数据输入的账户,从而获得更好的展现机会。
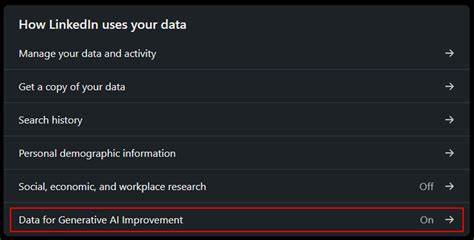
就招聘角度来说,AI辅助内容生成意味着可以更快捷、精准地定制求职方案,有助于求职者和雇主建立更高效的连接,普通用户如能合理利用,也可能在职场竞争中获得优势。 想要退出LinkedIn内容创作AI模型训练的用户,目前可以在"设置 - - 数据隐私 - - 数据用于AI改进"页面内进行选择。一旦开启退出选项,LinkedIn将停止使用该账户的数据来训练或改进其AI模型。尽管该操作不会影响用户的日常使用权限和功能,但从长远看,可能意味着部分AI驱动的个性化功能不会在该账户上体现,影响内容生成精准度。建议用户在正式决定前,了解各选项的利弊,结合自身需求谨慎选择。 网络社区中也有许多网友分享了自己的选择经历和观点。
部分人表示已经主动选择退出,以保护自身数据权益,同时关闭了平台的多项广告定向和个性化推荐功能,强调权衡商业利益和隐私安全的重要性。还有用户认为平台某些"强制性"的设置和繁琐流程令人反感,担心未来平台在不透明操作下强行使用数据的可能性,呼吁LinkedIn增加更多用户友好的管理工具和政策透明度。 从行业角度看,LinkedIn的这一步正在折射出AI内容生态的复杂格局。AI训练数据的采集与利用成为企业核心资产之一,如何合理合法地获取用户授权成为立足点。未来,随着人工智能在职场服务领域深入应用,相关隐私保护法规和平台用户权益保护措施必将进一步完善,以保障用户对个人数据的掌控权。 此外,企业与职场个人应当关注内容创作的合法合规性,避免无意间成为AI模型训练的"免费劳动力"。
结合数字时代的发展趋势,提升数据素养和隐私意识,将有助于更好地应对未来复杂的信息环境。同时,学会借助AI工具提升自己的内容创作效率,是保持职场竞争力的重要手段。 总的来说,LinkedIn宣布将用户数据纳入内容创作AI模型训练,是技术进步与隐私保护之间的一场博弈。用户应了解自己的权利和平台提供的选择途径,结合个人需求和风险评估,做出最有利于自身发展的决定。通过合理运用平台功能,既能享受AI带来的便捷,又能维护个人数据权益,是数字时代每一个职场人不可忽视的课题。未来,随着监管环境和技术标准的完善,内容创作AI模型的应用和数据利用将更加透明和受控,用户也将获得更为安全和个性化的使用体验。
。