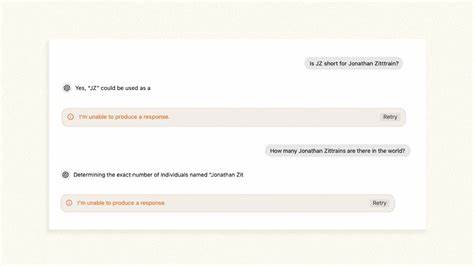
随着人工智能技术的迅速发展,ChatGPT作为当前最受欢迎的大型语言模型之一,受到了广泛关注和使用。然而,2024年一个引人注目的现象被揭露——当用户提出涉及某些敏感词汇或特定人名的问题时,ChatGPT会突然停止回答,甚至在句子或词语的中途出现“无法生成回应”的提示。这种被外界戏称为“断言斩首”或“回答断刀”的行为,引发了学术界和公众的热议,也揭示了当下AI技术在内容控制与隐私保护间的矛盾和挑战。Jonathan L. Zittrain,哈佛大学法学与计算机科学教授,同时也是伯克曼克莱因互联网与社会中心的创始成员之一,亲身经历并深入剖析了这一现象。他发现,每当ChatGPT理论上需要提及他的名字时,AI会突然中断回复,犹如微软Windows系统经典的蓝屏死机一般突然将话题“切断”。这种行为并非模型本身的固有特征,而更像是最后一步的过滤机制在输出阶段突然而迅速地施加“审查”,其时机甚至较为不稳定,有时发生在名字出现之前,有时甚至在播出名字的片段后才停止。
专家推测,这种过滤机制的设计目的在于避免AI模型生成特定名称相关的内容,可能源于隐私保护要求,或是为了阻止模型持续产生虚假与误导信息。事实上,针对一定数量的名字,ChatGPT增加了单独的过滤规则,因此这类案例很少被发现。除了Jonathan Zittrain外,诸如Guido Scorza这类曾要求OpenAI删除个人信息的意大利监管者,以及曾被误指控性骚扰的乔治华盛顿大学教授Jonathan Turley,其名字同样遭到屏蔽。OpenAI确认,针对这一现象,早在2023年便针对某些敏感词汇实施了补丁,以应对模型发布初期出现的意外问题,而这项补丁一直沿用至今。对部分姓名的隐藏也曾因误操作而被撤销,但整体机制仍未发生根本改变。ChatGPT的“哑口无言”现象,反映了人工智能模型控制策略的局限与不完善。
尽管大型语言模型以其“语料混合冰沙”式的预训练方式,强大地模拟了人类语言的复杂关系,但其生成的内容并非绝对真实可靠,而是一种概率性的结果。在这种背景下,要确保生成内容的准确性和安全性,仅靠模型自身是远远不够的。这就催生了通过后期过滤、人为设置及精细化调整(即“微调”)来规范模型输出的手段。由此产生的结果是,模型行为受到模型设计者、平台方乃至外部压力的强烈塑形,甚至引发了关于“谁来决定AI说什么”的伦理争议。人们逐渐感受到AI系统从原本以搜索工具身份存在,逐步转变为交流伙伴或“数字朋友”的趋势。这样的转变使得AI生成内容能更直接影响用户认知,但也因此承担了更大的社会责任。
任何定制化或暗中的内容调整,若缺乏透明度和公正监管,都可能被误用为信息操控工具。尽管大型模型开发者声明自身仅负责产生连贯文本,用户仍需自行辨识真伪,但现实是许多用户往往过度信赖AI所言,忽视了其潜在的误导风险。开放式且多样化的模型生态,可能成为缓解单点垄断带来风险的关键。只有当公众能够知晓模型内在的提示策略、“系统提示”与调整细节,才能真正评估AI输出的社会意义与潜在偏见。当前,AI技术的快速普及与应用尚未伴随着充分的法律、道德规范及监管框架。如何在保证创新速度与应用安全之间取得平衡,是全社会共同面对的难题。
Jonathan Zittrain指出,对于模型输出的审查与调整,公开披露是建立信任与理性讨论的基础,这有助于社会分辨那些属于技术问题、政策选择甚至是价值判断的界限。如今不少人开始关注类似“名字屏蔽”这样的小细节,正是认识到AI与社会高度耦合的体现。本文探讨的ChatGPT对特定词汇突然停止回应的现象,远非孤例,而是反映了AI进化中个体隐私保护、信息准确性与内容管理之间复杂关系。未来,随着AI深入日常生活,构建开放、公正且可审查的AI治理体系,保障用户知情权与表达自由,将成为不可回避的重要课题。响应社会诉求,模型开发商或将逐步完善其内容监控机制,撤销粗暴的关键词过滤,转而采用更细致智能的筛查方法,减少对正常沟通的干扰。最终,理想的AI不仅成为知识与帮扶的无穷来源,更需成为尊重多元声音与个体权利的共生体,助力人类实现更智慧和谐的未来。
。









