在现代软件开发中,处理不同语言的名字变化问题是一项颇具挑战的任务,尤其是像冰岛语这样富含复杂语法变格规则的语言。冰岛语中的人名会随着句子中所处的语法位置不同而呈现不同的形式,即词形变化(declension)。这种语言特性虽然极具表达力,但却给工程师们带来难度,因为数据库中通常只存储名字的主格形式,而实际应用中却往往需要使用其他语法格的形式。一方面错误地显示名字形态会破坏用户体验,另一方面人工编写变格规则代码极其繁复、且难以维护。为了更好地解决这个问题,开发者Alex Harri构建了一套基于Trie(字典树)和压缩技术的解决方案,将庞大的冰岛人名词形变化数据压缩至仅3.27 kB的体积,并将其封装为轻量级JavaScript库,使得Web应用能够精准处理各种格变化,优化用户界面表现。冰岛语名字的词形变化基本涵盖四个主要语法格:主格、宾格、与格和属格。
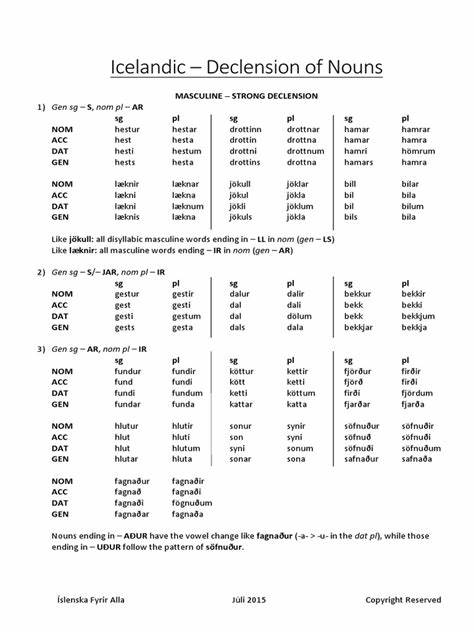
以名字“Guðmundur”为例,其在不同语法格中的形式依次是Guðmundur、Guðmund、Guðmundi、Guðmundar。由于句子结构决定需要使用的语法格,直接显示主格形式无法满足正确的语言规范,因此必须根据具体语法格转换名字形式。面对这一需求,传统做法往往是将所有带词形变化的名字完整储存或手写规则,但显然效率低下且难以扩展。Alex Harri选择了一种更加智能的数据驱动方式,首先借助冰岛Árnastofnun机构发布的数据库(DIM)中名词变化数据,这部分数据包含极其丰富的词形变化信息。但DIM数据庞大且不仅仅涵盖人名,为了精准定位冰岛核准的人名,开发者结合个人名字登记册进行过滤,最终获得约3600个名字对应的完整词形变化信息。直接存储这3600个名字的四个变化形式,数据量达到了30多kB,明显过大。
为此,他采用了基于最长公共前缀的技巧,把名字与其变化形式中重复的部分提取出来,用变格形式的后缀组成字符串,极大地节省存储空间。例如“Guðmundur”及其变形的最长公共前缀是“Guðmund”,后缀“ur,,i,ar”则对应四格的不同词尾。通过这种“后缀编码”方法,存储的是变格后缀而非完整形式。本质上,后缀编码抽象了词形变化的模式,脱离了具体名字,可以泛化应用于同一类后缀模式的名字。为了实现后缀编码模式的快速查询,构建了Trie结构,但Trie的键(名字)是反向插入的,即从名字末尾向开头插入,以便能把结构相似的名字词尾归为一类。例如所有以“ur”结尾的词会被聚集到同一子树,方便快速定位相似后缀的词形变化。
通过遍历Trie实现“反向查找”符合用户输入名字对应的后缀编码,进而推断目标格的词形。为了进一步降低Trie体积,对Trie子树进行了压缩:当某个子树的所有叶子节点对应同一词尾编码时,将它们压缩为子树根节点的值,移除多余节点。如此操作后,Trie大幅缩小,从原始的1万多个节点压缩到不足2000个节点,使查找路径大幅缩短,提升效率。然而,该方法虽有效,但也面临一个问题:对于词尾相似但存在微妙差异的名字,Trie压缩可能会无法正确区分所有情况,导致返回Null。对此,方案采用返回遍历过程中的最后匹配节点值的方法,兼容不能完美匹配的名字,提升泛化能力。经过测试,Trie不仅能准确处理输入数据的名字,对于未收录但词尾模式相似的名字也能给出合理猜测。
然而,依赖规则的压缩Trie仍存在少量约26%的错误率。基于实际数据和名字普及度分析,错误带来的整体影响较低,适合绝大多数用户场景。为了进一步减小体积,开发者实现了叶节点兄弟合并,将键包含相同子字符的叶节点融合为一个节点,极大降低叶节点数量,进一步压缩整体Trie体积至3.27 kB,最终轻松满足前端应用对体积的苛刻要求,并保持词形转换的高准确率。基于此技术构建的开源库beygla已经应用于多个实际场景,包括冰岛司法系统,在法庭文书中正确使用各种语法格形式的名字,提高了专业性和权威性。尽管如此,面向对语法准确度有极致需求的场合,也提供了严格版模块,保存完整词形变化数据以确保100%正确性,权衡体积与准确率。这种创新方法彰显了语言数据结构与压缩算法结合的潜力,极大推动语义计算的便捷与高效。
冰岛人名词形变化的解决之路展示了利用规则与数据驱动方式结合的必要性,以及Trie结构在语言技术中的巨大作用。未来,随着更多语言尤其是具有复杂格变化的斯拉夫语系和巴尔干语系纳入类似体系,词形变化模式压缩和推断方法有望大幅发展,从而为多语种软件开发带来革新。此外,该项目也强调了综合开源数据、详实规则归纳和算法创新结合的价值,为自然语言处理和语言资源开发提供了宝贵经验。总结来看,将冰岛人名词形变化数据压缩至3.27 kB的Trie结构,不仅极大降低了软件包体积,实现了高效词形变化功能,也以数据驱动方法避免了过度人工编码的复杂性,推动了民族语言数字化的进步。此外它还为类似复杂语言的词形变化问题解决提供了实用的范例。随着类似方案的推广,更多语言的语法细节有望得到恰当、简洁的计算机实现,从而丰富全球化人机交互体验与语言技术生态。
对于开发者、语言学家及应用使用者而言,此类轻量级且准确的语言处理工具,是迈向更自然、更智能软件交互的一大步。