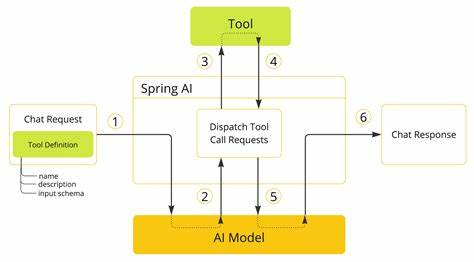
近年来,随着人工智能技术的快速发展,越来越多的开发者开始采用本地部署的模型(Local Models)来实现工具调用(Tool-Calling)。与依赖云端模型相比,本地模型具有更高的数据隐私性和响应速度优势,但在实际应用中,开发者却常常面临诸多挑战,导致工具调用的效果难以稳定。什么是本地模型的工具调用?通俗来说,就是通过模型的智能理解能力,驱动特定工具或接口完成某项任务,例如查询数据库、调用API、执行计算等。在云端大模型(如OpenAI GPT系列)的帮助下,这种调用常常较为顺利,因为它们经过精心设计与优化,带有自然的函数调用能力和较强的语言理解能力。然而,当开发者将目光转向本地模型时,便会遇到诸多阻碍。首当其冲的是工具调用的准确性问题。
许多开发者反馈,尽管他们的提示词设计得非常严谨、详细,但本地模型依旧会出错,有时调用的工具与预期不符,有时则完全没有触发工具调用,而是输出普通文本。这种不稳定带来的体验极其折磨人,尤其是在需要高可靠性的生产环境里。另外,一个核心困境源于本地模型自身的能力限制。相较于庞大且经过大规模训练的云端模型,许多本地模型体积较小,参数较少,甚至缺少专门的函数调用训练环节。因此它们在理解复杂的调用语境或者生成特定格式的调用命令时表现较差。即使是同一提示,结果也常常难以复现。
针对这一情况,社区中流传一些有效的提示策略。比如在提示词中明确说明工具调用的严格格式,借助示例引导模型按规范输出。这种"few-shot"或"chain-of-thought"提示技巧虽有一定作用,但其效果仍受到模型理解能力的限制,难以从根本上解决问题。还有一点值得关注的是推理引擎(Inference Engine)和客户端的表现对工具调用成功率的影响。不同的推理引擎在处理模型输出时是否能识别并正确解析工具调用格式,直接决定了整个流程的顺利与否。例如,有些引擎自带工具调用解析功能,能辅助模型完成流程衔接,而另一些则需开发者自行编写大量中间层代码,增加开发成本和维护难度。
开发者们也在不断尝试引入专门设计的函数调用模型,这类模型在训练时加入了函数调用的监督信号,使其能够更准确地生成函数调用格式以及参数。这种模型虽然在一定程度上缓解了工具调用问题,但普及度较低且多以云端服务存在,本地模型对应版本仍在研发阶段。此外,库和框架的支持也是能显著影响工具调用体验的关键因素。LangChain、Agent-style架构等工具正在帮助用户梳理并管理复杂的工具调用逻辑,减少重复造轮子。不过,大部分这类工具在本地模型场景中的兼容性还不够理想,需要专业调试与适配。从更高层面来看,工具调用的核心挑战还体现了自然语言理解和结构化调用之间的鸿沟:模型需要一方面理解人类输入的自由语言,另一方面又必须在输出层面产生格式化、符合接口规范的指令。
这个矛盾在小型本地模型中尤为突出,因为它们缺乏云端大模型中丰富的任务指示训练资源。针对这一困境,部分开发者开始探索结合规则引擎与模型输出的混合方案,通过预先定义模板与正则解析增强模型输出的规范化,提升工具调用的稳定度。此外,多模型组合策略也逐渐受到青睐。例如,使用一个轻量级模型负责命令解析,再由高性能模型完成语言理解,从而兼顾性能与准确度。未来,随着本地模型技术的成熟,尤其是在模型架构和训练方法的创新方面,工具调用场景必将获得更加稳定和高效的支持。开发者可以期待专门针对工具调用进行训练的本地化模型,以及更加智能的推理引擎和完善的框架配套,助力实现真正的离线智能工具生态。
然而目前,想要实现流畅稳定的工具调用,仍需开发者投入大量时间进行提示工程优化、推理环境调试和调用逻辑设计。总结来看,本地模型的工具调用依然处于一个"磨合期",面对较高的门槛和不确定性,社区经验的分享显得尤为珍贵。只有持续探索合适的提示策略,结合先进的推理技术与框架支持,并推动专门工具调用模型的发展,才能真正突破本地模型工具调用的瓶颈,释放其全部潜力。对于有志于这一领域的开发者而言,关注本地模型与工具调用的潜在难点,积极试验多样手段,并参与社区交流无疑是重要的成功路径。随着技术不断进步,这一方向势必将带来更多的创新解决方案,推动AI应用走向更广泛和深入的本地化进程,真正实现工具智能调用的自主、高效与可靠。 。