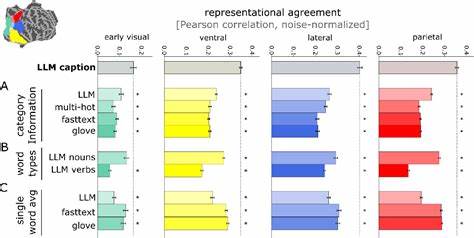
视觉是人类感知世界的重要方式之一,大脑通过复杂的神经网络系统将视觉信息转化为多层次、多维度的表征,帮助我们理解周围环境。长期以来,科学界对大脑如何处理视觉信息,尤其是在高级视觉区中如何编码场景的复杂语义关系,仍缺乏一种既能涵盖信息复杂度又具备可量化分析路径的统一表征形式。近年来,人工智能领域的高速发展,尤其是大型语言模型(LLMs)的兴起,提供了崭新的视角和工具,助力科学家揭示人脑视觉表征的深层机制。 大型语言模型通过训练海量文本数据,能够在"语义嵌入"空间中捕捉丰富的上下文信息和世界知识。这些模型不仅限于对单词和短语的理解,而是能整合整句甚至更长篇幅的语言信息,形成高维度的语义表示。令人惊讶的是,研究表明人脑在观看自然场景时所激发的高级视觉区域活动,能通过这些LLM语义嵌入形式进行高度拟合和预测,显示出视觉与语言认知之间意想不到的结构性重合。
科学家利用7特斯拉高场功能磁共振成像(fMRI)技术,采集了多名被试观看数千幅复杂自然场景时的大脑活动数据。这些视觉刺激均对应于使用微软COCO数据库中的人类手工标注场景描述。通过对这些描述进行大型语言模型处理,提取句子级别的语义向量,研究者将之与脑神经活动建立对应关系。运用多变量模式分析和表征相似性分析(RSA),证明了多种高级视觉皮层区域的神经表征能够被LLM的语义嵌入显著解释,而且模型预测的脑区响应模式与实际观察到的高度一致。 更进一步的是,研究人员基于神经活动成功解码出对应场景的文本描述,展现了逆向映射的潜力。这种解码帮助确认,人脑视觉系统的高级表征形式极有可能类似于LLM中捕捉的跨词语语义与上下文的融合方式,而非简单的对象识别或词汇分类。
对比实验还表明,单纯的物体类别标签和单词嵌入难以达到同样的拟合效果,强调了语义整合与多维上下文信息的关键作用。 为了验证这一假设,研究者训练了递归卷积神经网络(RCNN),通过输入图像直接预测对应LLM语义嵌入形式。这种视觉输入到语言表征的映射网络,比传统的仅以物体类别为目标训练的模型,能更好地模拟人脑的视觉表征,展示出超越现有计算模型的表现。该技术不仅验证了人脑视觉处理高级表征的可能计算路径,也为神经网络模型设计提供了新思路,即借助语言模型构造的丰富语义空间指导视觉信息的提取和编码。 此外,多个不同架构和类型的LLM在此研究中表现一致,说明这种视角具有良好的泛化性和稳定性,而非某一具体模型的偶然产物。对文本中名词、动词与完整句子嵌入的比较实验进一步揭示,完整句子的语义整合能力对拟合脑表征尤为重要,而单一词汇的词向量无法充分捕捉视觉语义的多层次面貌。
这一系列研究成果不仅推动了视觉认知神经科学的定量研究,也为人工智能领域的视觉语言融合模型奠定了理论基础。通过映射人脑视皮层多层次功能,揭示其与语言语义空间的一致性,我们得以窥见人类认知系统如何高效整合视觉与语言信息。此外,这种研究框架为后续跨模态神经表征研究、脑机接口技术及认知疾病诊断等应用提供极具潜力的工具和理论支持。 未来,科研人员将继续探索多模态表征体系,包括将时间动态、语法结构和情境信息引入模型,以丰富对大脑视觉语义表征的认知。同时,研究也将拓展至不同任务环境和物种,检验语言模型与非语言系统间的关联限度。技术上,整合视听语言信息的联合训练模型或许可进一步接近脑信息处理的真实机制。
人脑与大型语言模型之间关于视觉场景表现形式的这种深度契合,标志着人类认知科学与人工智能融合研究的新高峰。随着更多跨学科方法的融合及大规模数据的积累,我们离真正揭开大脑视觉信息处理奥秘的目标越来越近,同时也为构建更加智能和人性化的AI系统奠定了坚实基础。 。