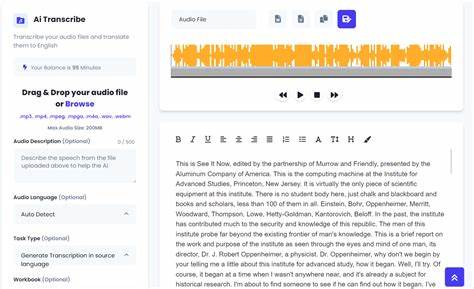
随着人工智能技术的迅猛发展,GPT等大型语言模型已成为自然语言处理领域的重要工具。然而,尽管GPT在文本生成和理解方面表现卓越,但在某些具体应用场景中仍存在局限性,尤其是在对文件中文本进行准确高亮处理时。这一不足激发了一些技术爱好者和开发者的创造性思考,从而催生了更为专注和高效的研究代理。研究代理的出现,正是为了弥补GPT在文本高亮方面的短板,提升用户在信息检索与分析过程中的体验。传统的GPT运行机制侧重于生成连贯的文本回复,其设计并非针对文件中细致的文本定位或标注任务。这种根本性的架构差异使得GPT在处理文件中的精确文本高亮时容易出现错误,影响用户对关键信息的获取。
与此同时,文件类型多样、格式复杂也增加了高亮的难度。面对这种局限,开发者开始构建以研究任务为核心的智能代理系统,这些系统能够基于文件结构和内容语义进行精准的文本定位与标注,从而帮助用户快速锁定关键信息片段。这类研究代理通常结合了自然语言理解、信息抽取和文件解析等技术,能够识别文本中的关键词、主题句及关联内容,实现类似人类专家的高效阅读和摘录能力。研究代理不仅针对文件级的文本高亮问题进行了优化,还更注重与用户交互的灵活性,实现对查询的深度理解及动态调整标注策略。例如,用户可以通过自然语言指定所需关注的内容范围,代理便会智能匹配相关文本并精准高亮,无需传统繁琐的手动筛选。构建高效研究代理面临一定技术挑战。
首先,文本高亮需要结合上下文理解,避免单纯的关键词匹配导致的误标,同时还要考虑文件格式多样带来的解析难题。其次,代理需要实时响应用户输入并保持操作流畅,要求系统具备强大的处理能力和优化算法。针对这些难点,开发者通常采用多模型融合策略,结合基础模型的语言理解优势与专门的文本解析算法。同时,通过引入反馈机制,研究代理能进一步学习用户偏好,持续优化高亮效果。这一创新思路不仅解决了GPT在文本高亮中的不足,也为其他自然语言处理任务提供了启示。在信息爆炸的时代背景下,精准且高效的信息摘录变得尤为重要,研究代理的出现大幅提升了研究工作者和知识工作者的信息处理效率。
实际上,研究代理的意义还在于其扩展了人工智能应用的边界。从最初辅助生成文本到现在主动参与信息筛选和标注,AI工具正在变得更加智能和专注,服务于更复杂的实际需求。未来,随着技术的不断迭代,这类代理将融合更多智能感知和理解能力,甚至实现跨领域、多模态的信息研究,为用户提供更深层次的知识挖掘支持。总之,研究代理应运而生,正是为了填补GPT在文件文本高亮中的空白。通过智能解析与动态交互,研究代理显著提升了文本处理的准确度与效率,极大地方便了知识获取和研究分析。随着技术的发展,这一领域必将迎来更多创新应用,为用户带来更优质的数字信息体验。
。