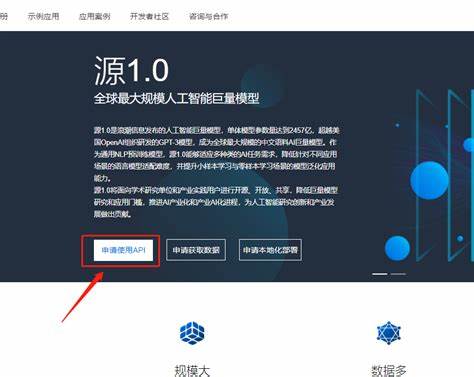
在现代人工智能的领域,预训练语言模型的迅猛发展引发了广泛的关注。随着技术的进步,越来越多的研究者和开发者致力于创建更强大、更智能的语言模型,以满足不断增长的自然语言处理需求。在这个背景下,Shawn-IEITSystems的Yuan-1.0引起了行业内外的瞩目,成为大型预训练语言模型的一个重要里程碑。 Yuan-1.0是目前最大的单体语言模型之一,拥有高达2460亿个参数。这一庞大的参数规模,使得Yuan-1.0能够在许多自然语言处理(NLP)任务中实现出色的表现,尤其是在零样本学习(Zero-Shot Learning)和少样本学习(Few-Shot Learning)领域。与之前的大型语言模型如GPT-3相比,Yuan-1.0不仅在技术上有了突破,更是在数据处理和模型架构设计上进行了创新。
在构建Yuan-1.0时,研究团队采用了大型分布式训练的性能优化作为模型架构设计的核心思路。这一方法的应用,使得模型训练的效率得到了显著提升,能够在成千上万的GPU上实现高效的并行训练。此外,团队还提出了一种新的数据处理方法,能够有效地从互联网上筛选出海量的数据,从而建立了一个容量达5TB的高质量中文文本语料库。这一语料库被认为是当前最大的中文文本集合,为Yuan-1.0的训练提供了丰富的训练数据。 Yuan-1.0的另一个显著特点是其在零样本学习和少样本学习方面的卓越表现。在相对较少的示例数据的情况下,模型仍能进行有效的推断和生成。
这一能力的增强得益于研究团队提出的基于标定和标签扩展的方法,经过多次实验验证,Yuan-1.0在多个NLP任务中的表现稳步提升。此外,Yuan-1.0生成的文章质量非常高,已经难以与人类撰写的文章区分开来,这使得其在生成文本方面展现出强大的潜力。 作为开源项目,Yuan-1.0不仅仅是一个单一的模型。研究团队承诺将开源1TB的语料库和Yuan模型的API,允许研究者和开发者便捷地进行模型的微调,以及实现少样本和零样本学习。这种开源的方式不仅增强了模型的可用性,还促进了人工智能领域的协作与创新。此外,研究团队还鼓励用户提交申请,获取使用Yuan-1.0 API的资格,这进一步推动了技术的传播。
为了方便用户使用Yuan-1.0,团队为其提供了详细的使用说明和示例代码。这些指导不仅涵盖了如何安装必要的Python库,还提供了各种应用场景的配置示例。例如,用户可以使用Yuan-1.0进行对话生成、内容续写、诗歌创作、关键词抽取与翻译等多种任务。这些应用场景展示了Yuan-1.0作为通用语言处理工具的潜力,让更多的开发者能够借助这一工具快速构建自己的应用。 在技术进步的同时,Yuan-1.0的发布也引发了关于人工智能伦理和社会影响的讨论。随着语言模型的能力不断增强,人们开始关注这些技术如何影响信息生成、透明度和内容的真实性。
研究团队在发布Yuan-1.0时,也表达了对这些问题的重视,强调在使用这种技术时必须谨慎,以确保其应用能够带来正面的社会价值。 Yuan-1.0不仅是技术创新的代表,也是对未来人工智能发展的展望。随着数据的不断积累和计算能力的提升,我们可以预见,像Yuan-1.0这样的模型在未来将会在更多的领域中发挥重要作用。从教育、医疗到金融、媒体,语言模型的应用将不断拓展,推动各行各业的数字化转型。 总体而言,Yuan-1.0是大型预训练语言模型的一项重要进展,它在多个方面都展示了令人瞩目的能力。通过开源和API的提供,Yuan-1.0不仅为研究者和开发者提供了强大的工具,也为进一步的研究和商业应用打开了新的大门。
无论是在技术层面还是社会层面,Yuan-1.0都将成为推动人工智能发展的关键力量,值得我们持续关注和研究。 在未来,我们期望能够看到更多基于Yuan-1.0的创新应用和研究成果,以及更广泛的技术合作与交流。这一切都将为人类的智能化进程提供强大的推动力,让我们的生活和工作更加便捷、高效。正如Yuan-1.0所代表的,不断追求创新与进步的精神,将永远引领着我们迈向更加光明的未来。