确定性无环有限状态自动机,英文简称为DAFSA,是计算机科学领域中一种极具代表性的数据结构,用于高效存储和快速查询字符串集合。作为一种有限状态识别器,DAFSA以有向无环图的形式表现,其独特的结构设计使其在众多应用场景中展示出卓越的性能优势。本文将从DAFSA的定义、历史沿革、与传统数据结构如Trie的对比以及实际应用等多个维度展开全面阐述,帮助读者系统理解这一高效字符串存储机制。确定性无环有限状态自动机的核心特征在于它的有向无环图结构。该结构由一个单一的源节点(没有任何入边)开始,图中的每条边都标记着一个字母或符号。每个顶点保证对于每个可能的符号最多只有一个出边,这种确定性保证了字符串匹配查询过程中路径的唯一性。
字符串集合通过从源点沿着边标签组成的路径到达无出边的终点节点来表示,因此DAFSA能够准确识别有限个字符串集合中的每一个元素。事实上,一个确定性有限状态自动机仅当其为无环时,才识别有限集合的字符串。DAFSA的起源可以追溯到多个重要研究。1983年,Blumer等人首次提出了“有向无环单词图”(DAWG)这一术语用于描述这一类结构。随后,Appel与Jacobsen在1988年提出了同名但实现细节有所不同的数据结构。最终,2000年Daciuk及其团队独立发现了该结构并以DAFSA命名,推动了相关算法及应用的广泛发展。
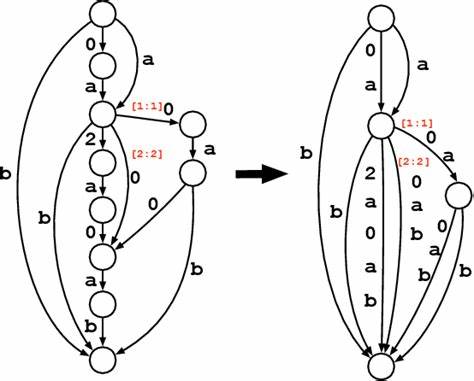
与传统的Trie树相比,DAFSA通过允许多个路径重用相同顶点,大幅节约了存储空间。Trie结构通过共享字符串前缀来节省存储,但对于后缀和子串的冗余并未优化。相比之下,DAFSA能消除前缀、后缀甚至中缀的重复节点,极大提高了存储效率。举例来说,对于四个英语单词“tap”、“taps”、“top”和“tops”,Trie存储需要12个顶点,而DAFSA仅需6个顶点即可表达相同的字符串集合。虽然DAFSA在空间利用上更具优势,但其也带来了功能上的限制。由于终端节点可能由多条路径访问,DAFSA不适合直接存储与特定路径绑定的辅助信息,如词频统计等。
但是,通过为节点存储通过该点的唯一路径数量,可以实现诸如根据索引检索单词等功能,辅助信息则可独立保存在数组中。DAFSA的构建和维护依赖于高效算法,保证了结构的最小性和增量构造能力,使其在动态字符串集操作中具有实用价值。通过不断合并等价子图,DAFSA避免了重复状态的产生,实现了空间最优。其查询时间与字符串长度成正比,适合对大量字符串集合做快速成员测试。这一特性在词典检索、拼写检查、语音识别和自然语言处理等领域中发挥了重要作用。在拼写校验应用中,DAFSA能够高效地判断输入单词是否存在于词典中,同时保持词典数据的压缩和快速访问。
在语音识别系统中,DAFSA帮助实现对正确词汇的快速判定,有效减少识别延迟。除此之外,DAFSA还被广泛用于搜索引擎、信息检索和代码分析工具中,用以提高海量字符串的处理效率。尽管DAFSA在内存优化和搜索效率方面表现优异,但其结构复杂度较Trie更大,设计和实现难度也相对较高。开发者需要深入理解状态合并、最小化算法及无环图特性,确保数据结构的正确性和性能。近年来,随着计算能力的提升及大数据需求的增长,开源社区推出了多种DAFSA实现库,如Python的DAFSA库,进一步降低了该结构的使用门槛。结合现代计算环境,DAFSA的发展仍有很大潜力,特别是在机器学习、自然语言理解、复杂数据结构优化等方向。
总结来说,确定性无环有限状态自动机通过消除字符串存储中的冗余节点,显著节省了存储空间,提高了查询效率,是处理有限字符串集合的理想选择。其独特的结构设计和应用价值为众多计算领域带来了性能提升,并在理论和实践层面均具备重要意义。未来,随着算法优化和应用需求的不断深化,DAFSA将在更多场景中展现其独特优势,推动字符串处理技术的创新发展。