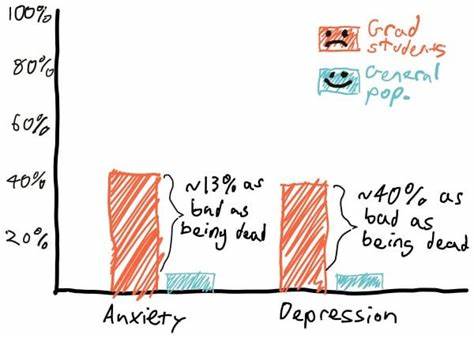
在现代数据分析和实时监控系统中,时间序列数据扮演着至关重要的角色。准确高效地处理海量时间戳数据,尤其是在有限存储空间内进行统计聚合,成为系统设计中的核心挑战。桶式时间序列(Bucketed Time Series)作为一种常见且高效的解决方案,依靠将时间周期划分为多个“桶”来收集和整理数据,实现了滚动窗口的统计功能。而在此过程中,整数除法发挥了关键作用,影响着时间和桶索引之间的映射精度和系统性能。本文将深入探讨桶式时间序列中两种主要的整数除法技巧——向下取整的整数除法和向上取整的整数除法,揭示它们背后的数学原理及其在实际开发中的应用意义。 桶式时间序列的设计初衷是为了在有限的存储桶数量内,连续跟踪某个指标在一定时间范围内的变化。
以网页浏览量统计为例,系统可能希望在一分钟内按秒拆分成60个桶,每个桶内累计该秒内的浏览次数。时间序列本质上是一个环形缓冲区,将时间映射到桶索引,随着时间流逝,旧数据被覆写,实现滚动更新。 实现这一映射的关键在于准确、高效地将时间戳指向对应的桶索引。Folly库中,BucketedTimeSeries类利用了整数除法技术完成这一工作。首先,通过计算当前时间相对于周期时长的位移,乘以桶数量,再除以整个周期的时长,以获得桶索引。这里的整数除法采用向下取整(floor division),确保在时间向前推进时,所有处于同一个桶区间的时间点均被指向同一索引,避免误差产生不一致。
由于时间和桶分配通常不是整数倍数,向下取整的整数除法导致部分周期无法均匀划分,但这一缺陷被设计者容忍,因为它保证了索引的稳定和不会“跨桶”错误聚合。此外,整数除法的高效性使得系统处理延迟大幅降低,尤其适合高频率的数据采集场景。 另一方面,当系统需要根据桶索引计算对应桶的起始时间时,应用了另一种数学技巧:向上取整的整数除法(ceiling division)。这一过程基本上是将桶索引乘以周期时长,再加上一个调整因子后进行整数除法,从而准确计算出每个桶区间的起始时间戳。 使用向上取整的原因在于保证每个桶的起点不会因为除法取整而产生偏移,否则会出现时间戳落入错误桶的情况。也就是说,通过这种方式,系统能够准确判断新采样是否属于当前桶,或已越过边界进入下一个时间段。
这个设计保证了时间和桶索引之间的双向映射一致性,从而维护了时间序列数据的完整性和正确性。 细致观察可以发现,这对“向下取整”和“向上取整”的整数除法技术相辅相成,共同构成了时间戳与桶索引间映射的数学基础。实际上, 向下取整确保任何起始时间点映射至对应的桶索引,而向上取整则确保每个桶索引对应的起始时间正确反映桶区间。这种设计不仅美观,更极大地增强了时间序列统计的可靠性。 数学上证明,这一对技巧之所以正确且有效,是基于桶的数量不超过周期的刻度数的内在约束条件。若桶数大于周期刻度,映射便会失真,而在实际应用中,这种约束天然符合系统设计逻辑。
该证明也表明即便周期长度和桶数不整除,算法依然可以确保映射的双向一致性,避免数据错位。 此外,这些整数除法技巧还有助于提升系统的性能表现。浮点数除法和取整操作普遍比整数除法昂贵,而在大数据高频处理场景中,性能差异被放大。利用整数除法确保计算过程轻量且确定,更易实现硬件加速或低延迟任务。 Folly库的BucketedTimeSeries为社区展示了这一巧妙设计的范例,体现了计算机科学中数学理论与工程实践的完美融合。对于研发人员而言,理解并掌握这些技巧,不仅能够有效复用现有成熟方案,还能启发设计更高效、精确的时间序列处理机制。
展望未来,随着数据采集和分析规模的持续扩大,时间序列数据处理的性能和精度需求将不断提升。桶式时间序列通过合理利用整数除法技术,实现了空间和计算上的双重最优化,成为诸多实时监控、指标统计系统首选的技术手段。深入理解其核心原理,有助于开发者在复杂应用环境下做出更优设计决策。 综上所述,桶式时间序列中整数除法的使用不仅是数学上的精巧妙思,也是保障系统性能和数据准确性的根本所在。向下取整和向上取整的巧妙配合,实现了时间戳和桶索引之间精准且高效的双向映射,这一设计理念值得广大程序员和系统架构师深入研究和借鉴。通过合理安排桶数与周期关系,充分发挥整数除法的优势,能够极大提升时间序列数据处理系统的稳定性与响应速度,为大规模数据分析和在线服务监控铺设坚实基础。
。