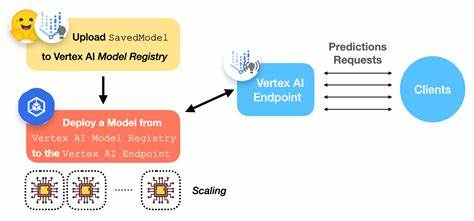
近年来,随着人工智能技术的不断发展,开源模型因其灵活性和强大能力,成为开发人员和企业构建生成式人工智能应用的重要选择。然而,如何有效地将这些开源模型从初步发现阶段,经过定制化微调,再到最终在云端实现生产级别部署,成为了困扰众多AI工程师的难题。传统方式往往涉及复杂的依赖管理、硬件资源调配以及基础设施搭建,尤其是对于需要高性能GPU加速的任务,更是让人头疼。谷歌云推出的Vertex AI为开发者提供一站式解决方案,大大降低了这种技术门槛,助力用户高效完成模型的全生命周期管理。从发现开源模型到将其部署成生产端点的整个过程,本文将结合Qwen3模型的应用示例,系统介绍如何利用Vertex AI实现端到端的AI模型开发。首先寻找合适的基础模型是成功的第一步。
开源模型种类繁多,选择合适的模型和硬件配置往往耗费大量时间。Vertex AI提供了Model Garden这样一个精选模型库,囊括了数百个已验证模型,包括Qwen、Gemma、DeepSeek及Llama等知名模型。这个模型中心不仅提供详尽的模型信息卡,还会给出推荐的硬件规格,让用户可以针对应用需求选择最优方案。更值得信赖的是,所有模型及其容器都经过安全扫描,最大限度降低潜在风险。找到心仪的模型后,Model Garden支持一键部署,或者提供预配置的Jupyter Notebook,帮助用户快速将模型转换为Vertex AI推理服务的端点,方便集成进实际应用。部署选项还包括性能优化的服务容器,常用框架如vLLM、SGLang或Hex-LLM等,确保模型推理具备高吞吐和低延迟。
启动初始测试后,务必利用Vertex AI的生成式AI评估服务或开源评测工具,对模型在目标任务中的表现进行量化验证,为后续定制微调奠定数据基础。微调是打造定制化AI应用的关键环节。选择了Qwen3作为基模型后,就可以开始依据自身场景输入专门数据,实现模型风格和知识的个性化塑造。数据准备通常会成为瓶颈,Vertex AI则支持直接读取Google Cloud Storage和BigQuery中的数据,同时提供可视化流水线,助力复杂的数据清洗和预处理工作自动化完成。在调优环节,Model Garden提供配套的Axolotl框架内核的Notebook,集成多种高效策略,如QLoRA和FSDP,让用户能在受限资源下也能完成实验验证。笔记本环境适合快速反复试验,寻找微调的最佳超参数配置。
待经验积累后,用户可以升级到Vertex AI托管训练服务,享用弹性伸缩的GPU资源调度,以及无需运维的可靠基础设施,确保大规模训练任务安全高效进行。借助实时监控工具如TensorBoard,训练过程中的关键指标都能清晰呈现,提升调试效率。此外,针对高级场景,还可结合Ray on Vertex或自行搭建GKE/GCE集群,以满足特殊定制化需求。完成微调后,评估工作必不可少。Vertex AI的生成式AI评估服务能运用“裁判”模型对文本生成结果从连贯性、相关性、可信度等多维度打分,配合人工侧评实现模型性能的深入洞察。通过编程接口,开发者可批量比较微调后模型和基模型的表现差异,为后续迭代改进提供科学依据。
在具体项目中,可以利用配套的评估Notebook辅助实现流程,增强开发的便利性。整个过程贯穿始终的是生产端部署的平稳和高效。Vertex AI Inference服务通过与领先的推理引擎结合,打造出低延迟、高吞吐的生产级服务环境。同时,在启动速度、模型权重加载和缓存机制等方面持续优化,确保应用可快速响应用户需求。为了兼顾成本和灵活性,平台支持多样化GPU计费模式,包括按需购买、预留折扣、动态负载调度及低价的Spot虚拟机,用户可根据业务特性自由权衡资源投入。底层完全托管的服务让开发者无需关注运维细节,专注业务创新。
总而言之,在Vertex AI平台的支持下,从海量开源模型中筛选合适基础模型,通过高效的数据流水线实现个性化微调,再借助先进评估体系验证模型效果,最终将其部署为可弹性扩展、高性能的生产端点,整个流程变得前所未有的简洁且高效。Qwen3只是众多模型中的一个示例,开发者可以根据实际需求选择平台丰富的模型资源,快速启动人工智能项目,缩短从实验室到生产的周期。未来,随着技术演进和开源生态的壮大,Vertex AI将在开源模型的管理与应用领域扮演越来越重要的角色,助力更多企业和开发者轻松驾驭生成式AI的巨大潜力。









