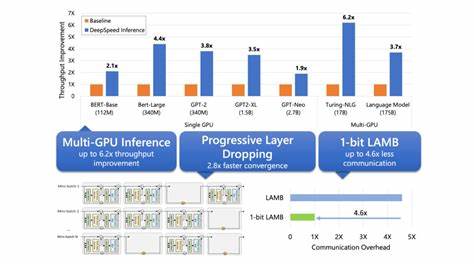
近年来,生成式人工智能领域迎来了前所未有的发展,图像生成、音频合成以及语音识别技术快速进步,深刻改变了人们的生活和工作方式。尤其是大型机器学习模型凭借卓越的性能展现出强大的应用潜力。然而,这些模型体积庞大,参数数量惊人,如何将其高效地运行在资源受限的移动设备上,成为当前机器学习领域的一大挑战。传统的服务器部署虽能提供极致性能,但面临隐私安全、网络依赖及能耗等问题,促使研究者和工程师纷纷寻求“设备端推理”的技术突破。GPU作为移动设备上最具普及性和计算能力的AI加速器,因其并行计算优势而备受青睐。尽管如此,将超大规模生成模型直接部署于手机或笔记本GPU仍存在复杂的硬件兼容性、多GPU接口协同以及性能瓶颈等多重障碍。
面向这一生态难题,最新的GPU加速推理框架“ML Drift”应运而生,成为推动大规模生成模型本地推理的革命性引擎。ML Drift不仅支持比以往模型大10至100倍的参数规模,更通过优化跨GPU接口和适配多平台体系结构,突破了移动与桌面环境的多样化限制。其核心优势在于实现了现有开源GPU推理引擎难以企及的性能提升,达到数量级的效率跃迁。用户在无需依赖云端服务的情况下,即可享受到复杂生成任务的流畅体验,同时保障个人数据的安全和隐私。ML Drift的设计理念充分考虑了移动应用的能耗管理和实时响应需求,通过精细的资源调度和内存优化技术,减少了冗余计算和能量浪费,使得大型模型推理变得更加可持续和实用。此外,跨多种操作系统和硬件架构的无缝兼容性,极大地拓展了其应用场景,从智能手机、平板到笔记本电脑,都能获得高性能生成模型的加持。
在实际应用层面,ML Drift助力智能摄影、个性化语音助手、实时翻译等多种生成式AI服务实现端侧部署,不仅缩短了响应延迟,还提升了交互的流畅性和自然性。隐私方面,数据无需上传至服务器,使用户能更好掌控个人信息安全,迎合了日益严苛的监管环境和用户隐私诉求。开源社区对ML Drift的积极响应也推动了相关技术的迭代升级,形成了良好的生态闭环,促进更多开发者和厂商参与创新,共同拓展生成模型的边界。未来,随着硬件性能的持续提升和算法优化的不断深化,基于ML Drift等框架的移动端大规模GPU推理将成为主流趋势,带来更丰富的智能体验和更多元的应用场景。这项技术不仅为产业链上下游提供了坚实基础,也为人机交互模式的变革注入新动力。总结来看,将庞大的生成模型高效、安全地运行于移动设备,是人类迈向真正普惠智能生活的重要里程碑。
通过突破传统服务器限制,借助GPU并行加速与ML Drift框架的创新设计,设备端推理的未来充满无限可能,值得各界持续关注与投入。对于广大用户而言,意味着更聪明、更快、更私密的智能服务触手可及;对于企业和开发者,则是一场技术革新及市场机遇的盛宴。