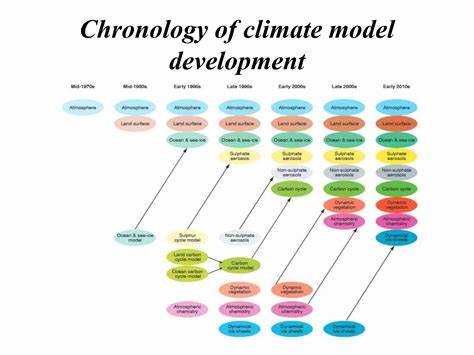
气候模型长期以来被视为理解地球系统与预测未来气候的权威工具。但在科研之外的另一面,气候模型本质上是由人类编写、维护和扩展的大型软件。正因为由人编写,错误不可避免。本文聚焦气候模型开发者如何应对这些"bug"(程序缺陷),以 ICON 开发实践为切入点,解析发现、判断、调试、修复与传播的现实运作,并讨论测试体系、透明度与"good enough(足够好)"判断对科学可信度与社会应用的意义。 将气候模型视为软件而非纯粹的理论工具,能帮助理解为何错误既常见又难以完全消除。像 ICON 这样的通用环流模型包含数百万行代码,牵涉到众多物理过程的离散化、耦合机制、数据接口以及并行化实现。
规模大、接口复杂与模块间隐性依赖导致单个开发者难以把握全部细节,代码的可观测性与输入输出之间的"认知不透明性"使得定位缺陷变得艰难。 在实际开发中,发现 bug 的路径往往并非系统化的漏洞扫描,而更像日常工作中的巧合:某次性能测试发现某个模块表现异常,某次阅读或重构旧代码时发现数学项被遗漏,或是长期运行的监测图出现不合理漂移。以 ICON-Sapphire 的高分辨率开发为例,在提高到公里级网格时,许多参数化被关闭或改写,曾经稳定的数值实现被重新触发,于是大量原先被掩盖的问题浮出水面。开发者经常在进行其他工作时顺带发现潜在缺陷,而非在专门寻找 bug 的情况下发现它们。 一旦产生怀疑,团队会展开诊断流程,但这一步骤并无统一模板。确认问题是程序缺陷而不是模型固有的不精确,常常需要多方讨论、实验设计与对比分析。
存在一种"oracle problem(无绝对参考)":气候模型没有单一的、绝对正确的输出可作为判断标准。同时还有"tolerance problem(可容忍误差)",历史上被接受的近似实现可能掩盖了真实的缺陷。开发者需要结合物理理论、观测对比、多模式比较以及经验判断来决定是否进入深入调试环节。 调试阶段更多地像科学研究本身,开发者通过提出假设、设计简化测例、逐步隔离变量来定位错误。常见做法包括运行对照版本、提高诊断输出频率、插入打印语句、借助调试器、对比不同编译器的行为,以及在专门的测试配置中复现问题。复杂的软件生态也带来了新的调试难点,例如 GPU 加速时代的 host-to-device 同步遗漏,或是在并行环境中由于错误索引导致的竞争条件。
硬件故障亦可能伪装成软件 bug,像内存模块衰退会造成写入与读取不一致,从而让模拟在某些运行节点上频繁崩溃。 做出修复决策时,开发者除了寻求修复根本原因外,还要权衡性能、代码可维护性、模块设计一致性以及短期可行性。面对紧迫的科研项目与有限的工程资源,常出现先做临时权宜之计以确保模拟可继续进行,再在后续版本中引入系统性长远修复的情形。举例而言,能量守恒性出现泄漏时,团队可能先通过诊断并把残余能量合并到耗散加热中作为短期补偿,长远方案则是引入总能量方程来让模型内在守恒。这样的取舍反映出开发者在"完美修复"与"可用稳定"之间的现实平衡。 测试体系是减少与捕捉缺陷的关键环节,但在气候模型开发中面临多重挑战。
ICON 团队使用自动化测试平台(如 BuildBot)来运行技术性检测,确保变更不会在短期内破坏已有配置或导致编译器错误。这类测试擅长捕捉语法错误、接口变化或简单回归,但由于运行步数极少、覆盖配置有限,它无法代替对物理行为的长期评估。相比之下,针对科学正确性的测试需要理想化或解析解测试、完整耦合的生产级模拟以及长期的低分辨率回归实验。高分辨率仿真成本极高,使得常规回归测试变得昂贵甚至不可行。单位测试在新模块和底层库中逐步推广,但对整个历史代码库而言,施行完整的单元化改造几乎不现实。 电子化的协作平台在记录与沟通方面发挥重要作用。
GitLab 等版本控制和问题追踪系统为合并请求、问题单与提交信息提供可追溯的记录,使得团队成员能够查看谁修改了什么、为何修改及其讨论过程。然而,实践中仍存在不完全采纳的问题。一些领域科学家因合并流程繁琐或 BuildBot 要求较高,可能选择在本地修复后不提交回主干,导致修复缺乏公共记录。缺乏激励是个核心原因:修复软件缺陷通常难以直接产生学术成果,而开发与维护工作在现有学术评价体系中回报有限。 沟通缺陷的透明度对模型用户尤其重要。模型开发者往往通过内部会议或在问题追踪系统中闭环处理并关闭问题,但这样的隐性传播很难覆盖到外部用户与下游数据使用者。
随着 ICON 源码逐步公开,外部用户将能够直接查看提交与问题单,这有助于提高透明度,但同时也要求开发团队改进文档、提供易读的 bug 报告与修复摘要。提出建立中央化的"模型缺陷登记库"或专门的短篇缺陷报告类型,是提高透明度与使用户受益的可行方向。 "足够好"的心态在气候模型开发中普遍存在。开发者认识到完全无错的理想几乎不可达,而是在特定科学目标和工程资源约束下追求"adequacy for purpose(适配目的的充分性)"。这一策略并非消极妥协,而是一种务实的资源分配:哪些问题必须立即修复以保证科学结论的可靠性,哪些问题可以保留并在未来逐步处理。然而,"足够好"也引发重要伦理与治理问题。
谁来判断模型对于某一决策或科研用途是否"足够好"?当模型输出被用来影响政策、土地管理或基础设施投资时,用户与决策者需要理解潜在的模型不确定来源,包括可能的隐藏缺陷与已知的补丁措施。 模型信任的建立依赖于长期经验、多模式比较以及与观测的一致性。开发者通常在意识到 bug 存在的同时仍然信任模型产出,因为他们知道任何复杂软件都可能含有缺陷,且模型的适用性经过逐步验证与社区检验。然而,信任并不等于盲从。高质量的测试、详尽的诊断报告、透明的 bug 通讯和可复现的实验都是巩固用户信任的重要因素。减少信息不对称、明确已识别缺陷及其影响范围,可以让研究者更自信地使用模型输出,也能防止模型在公众政策领域被误读为"绝对真理"。
为改善气候模型中对 bug 的应对能力,可以从多个维度着手。增强自动化测试的覆盖范围并结合科学级回归套件有助于早期捕捉回归与物理异常。推广单元测试与模块化设计能降低未来维护成本。建立清晰的缺陷报告模板、鼓励将修复提交回主干并通过激励机制认可维护工作,会改变"不提交"的文化。硬件与性能监控也是关键,定期检查运行节点的内存与算力健康能够避免将硬件故障误判为软件缺陷。开放开发与共享错误案例库将帮助外部用户与合作伙伴更好地理解模型演化。
此外,培养跨学科的人才队伍十分重要。科学程序员与研究软件工程师(RSE)在连接科学问题与高质量软件工程实践方面发挥桥梁作用。支持长期的 RSE 职位、将软件维护纳入科研评价体系以及提供透明的培训资源,都有助于提升代码质量与减少长期维护负担。 面对快速演进的气候模拟需求,科研团队需要在追求性能与维护稳定性之间找到合适的平衡。高分辨率模拟带来了更细致的过程再现能力,也放大了数值不稳定性与实现细节对结果的影响。因此,项目在设计阶段就应权衡性能目标、测试策略与维护资源,并将这些决定以可理解的方式记录与传播。
总之,气候模型中的 bug 并非偶发现象,而是复杂工程与科学实践交织下的必然产物。理解开发者如何发现、判断、调试与修复这些缺陷,有助于增强模型的可解释性与可靠性。推行更完善的测试体系、提高文档与沟通透明度、鼓励将修复记录并开放共享,以及在学术评价与资金支持层面承认软件维护的价值,都是降低缺陷风险、提升模型可信度的可行路径。与此同时,面对"不可能完全无缺陷"的现实,明确"足够好"的标准与用途边界,对科学界与决策者而言同样具有重要意义。只有在工具的能力与局限都被坦诚对待之下,气候模型才能更可靠地服务于科研发现与社会决策。 。