随着大型语言模型(LLM)在自然语言处理领域的广泛应用,尤其是在文本生成、机器翻译及对话系统中,其推理能力和上下文处理长度不断攀升。然而,随之而来的内存需求也急剧增加,成为制约实际落地与广泛部署的重要瓶颈。其中,关键-数值(KV)缓存的高效管理成为核心难点。KV缓存记录了上下文中每个位置生成的键和值向量,是Transformer架构实现长距离依赖与上下文理解的关键数据结构。随着上下文长度和批处理规模的扩大,KV缓存的空间消耗呈指数级增长,往往达到数十甚至数百GB级别,严重限制了硬件资源的利用效率及推理速度。面对如此挑战,KVComp应运而生。
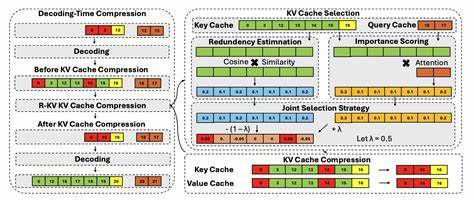
KVComp是一套专门面向LLM推理场景设计的高性能KV缓存管理框架,其核心创新在于引入有损压缩技术,结合KV缓存数据的特性,达到显著减小内存占用的目的,同时确保模型推理的准确性不受影响。传统的无损压缩方法在处理大规模KV缓存时既效率低下,又难以实现理想的压缩率。KVComp通过系统级和算法级的协同设计,智能压缩KV向量,实现存储空间和访问效率的最优均衡。KVComp在架构设计上兼顾延迟关键型和吞吐关键型的推理系统需求,为不同应用场景提供灵活适配。它不仅支持缓存的动态增长,还在压缩算法和解压缩过程优化了计算流水线,确保解压缩开销极低,甚至部分场景下提升了后续计算的执行速度。技术上,KVComp利用了KV数据的分布特征和语义冗余,采用适合向量数据的有损压缩策略,包括量化、主成分分析和低秩近似等手段。
同时,KVComp针对Transformer注意力模块对数据访问模式进行了深入分析,设计了轻量级的解码器,减少内存带宽占用。实验结果显示,KVComp在内存压缩率上平均提升47%,最高可达83%,在保障推理精度损失极小的情况下,显著降低内存需求。同时,由于数据移动量下降,KVComp提出的解压缩流程减少了CPU/GPU负载,提升整体推理吞吐效率,甚至在矩阵向量乘法中优于主流cuBLAS库的优化实现。在实际应用中,对长文本生成任务尤为重要。短文本推理时KV缓存相对较小,压缩优势不明显,但随着上下文长度扩展到数千甚至上万令牌,KVComp的作用愈发突出。许多对话式AI、智能写作辅助工具及知识问答系统可通过集成KVComp实现显著成本降低与性能提升。
此外,KVComp的开放框架设计有助于集成并拓展至更多类型的Transformer模型和硬件平台。它提供丰富的接口与API,方便开发者根据自身需求调整压缩策略和缓存管理方案。未来,随着更大规模及多模态模型的普及,对高效KV缓存管理技术的需求将持续增长,KVComp具有极大的应用前景和商业价值。总的来看,KVComp标志着LLM推理体系结构的一次重要升级。它通过面向KV缓存数据特点的有损压缩方案,突破了传统内存瓶颈限制,促进了模型推理规模与速度的双重提升。在当前算力资源紧张及模型需求不断增长的背景下,KVComp为行业提供了一条切实可行的优化路径。
未来的研究可以进一步挖掘KV向量的结构和语义信息,结合自适应压缩以及硬件协同设计,实现更智能、更高效的KV缓存管理。综上所述,KVComp不仅在技术上推动了LLM推理的进步,也为相关应用带来了实际价值,值得产业界和学术界的广泛关注与深入研究。 。