SQLite作为嵌入式数据库的典范,凭借其轻量、高效和零配置的特性,广泛应用于移动端、桌面端等众多场景。然而,随着应用需求的增大,数据库中存储的数据类型和长度也日益多样化,尤其是TEXT和BLOB等可变长字段,有时单行数据的大小会超过单个页面的存储容量。如何在这种情况下保证数据的完整性与高效访问,是SQLite设计中必须攻克的难题。SQLite设计了溢出页面机制(Overflow pages)来解决这一问题。本文将深入分析SQLite溢出页面的结构与工作原理,并结合Rust语言的源码实现,为开发者提供清晰的理解路径和实用参考。SQLite中每个页面默认大小通常为4096字节,但这并不是固定值,开发者或环境可能会根据需求调整页大小。
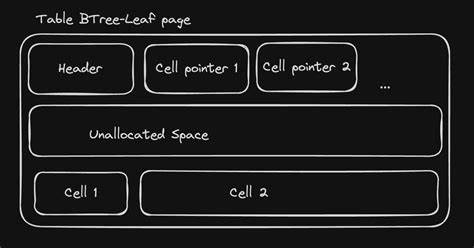
正常情况下,一条记录(row)的所有数据会被放置在一个页面的B树叶节点中,数据库内部实现通过页表(Pager)将物理页面映射为逻辑页面供操作使用。然而,一旦某条记录的字段数据超过了单页的可用空间,那么SQLite就会启动溢出机制,将超出部分的数据拆分存储到额外的溢出页面中。溢出页面结构采用链表形式,页面开头4字节存储下一个溢出页面的页号,如果为零,则表示溢出链表的尾页,随后紧跟实际的数据有效载荷。B树叶节点的Cell结构中,则包含该字段的前N个字节数据(称为本地有效载荷,Local Payload)和第一个溢出页面的页号指针。计算本地有效载荷长度主要依赖一组参数公式,包括页面大小、可用空间、溢出阈值阈和最小载荷尺寸等。具体来说,需要知道数据库头中存储的保留字节数(Reserved size),以便计算出可用页结构大小。
通过这些参数决定,如果记录数据在阈值范围内,则全部存储在叶节点,否则根据可用存储空间和溢出页面大小计算最优拆分点。用Rust实现时,先是通过解析数据库头得到页面大小和保留字节数,然后定义一个方法计算当前页面的本地有效载荷大小。该方法会根据给定数据长度调用对应规则,动态返回本地及溢出数据的大小。接下来,需要扩展页缓存机制让它支持存储普通页面和溢出页面两种类型。设计时定义一个枚举类型CachedPage,包含Page和Overflow两个变体,并为它们实现转换方法保证灵活调用。溢出页面的解析逻辑非常简洁,读取页面前4字节获取链表指针,剩余字节作为溢出数据。
在Pager模块,新增读取溢出页面的方法,延续同样的缓存与加载逻辑,保证溢出数据的访问效率和正确性。在访问数据库游标(Cursor)时,判断当前读取字段的结束偏移是否超出本地有效载荷长度,如果超过且存在溢出页面指针,则调用OverflowScanner通过链表逐页读取溢出数据,直到满足请求长度或链表终止为止。通过不断追加读取的溢出字节,实现对大字段的完整访问。同时,Cursor结构体维护下一个溢出页面指针,实现懒加载和数据续读,避免一次性加载过多内存消耗。全文来看,SQLite溢出页面设计主要解决了大字段数据页内无法容纳的问题,保证了数据存储的连续性且查询性能不至于因大字段受到严重影响。Rust实现版本不仅体现了溢出机制的细节,也充分利用了Rust的类型系统和并发控制特性,增强了代码的安全性和可维护性。
对于数据库开发者和存储引擎设计者而言,深入理解溢出页面的管理机制,是实现高效数据访问和查询优化的关键。未来的SQLite工作可以在此基础上,进一步优化溢出数据的访问策略,比如实现流式读取、索引加速溢出链条遍历,甚至多线程并发处理等方向展开提升。总结来说,SQLite的溢出页面方案简洁而高效,巧妙地使用链表结构对超大数据进行分片存储,同时借助本地有效载荷的动态计算优化内存利用率。通过对该机制的源码还原与讲解,开发者可以掌握数据分布与读取的底层逻辑,进而设计出更健壮和高性能的数据库应用。随着信息量爆炸式增长和多媒体数据存储需求不断增加,溢出页面机制的理解及相关技术的深化,将成为数据库领域不可或缺的重要组成部分。