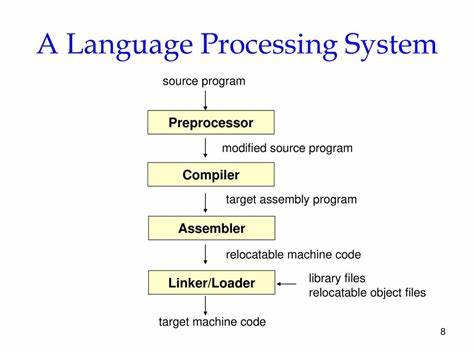
在现代软件开发的多样化环境中,预处理器作为源代码处理的重要工具,一直扮演着关键角色。传统的预处理器多以C语言为核心,紧密结合C或C++语言的语法结构,使其功能和应用范围较为有限。eĿlipsis(念作“ellipsis”)则打破了这一局限,作为一个语言无关的预处理器,开启了预处理器技术的新纪元。它不仅继承和扩展了C预处理器的优势,更致力于服务于更广泛的技术语言和文本处理领域,包括编程语言、文本标记语言、自然语言等多种场景。作为一个完全用C23标准编写的项目,eĿlipsis大量应用了现代C语言的新特性,以提高代码的可维护性和扩展性。eĿlipsis的设计目标非常明确。
首先,它力求提供一个完整且独立于C或C++语言规范的预处理器规范,这意味着它不仅是一个代码工具,还是一个可以被其他语言和工具参照的标准。其次,eĿlipsis关注不同语言的语法特性,努力打造适用于多种技术语言的预处理能力。当前,eĿlipsis已支持对lex词法分析器,以及html和markdown等文本处理语言的初步支持,展现出其广泛的应用潜力。此外,它采用现代Unicode标准,极大地改善了对算术公式、技术术语和自然语言专有名词的支持能力,确保国际化文本能够被高效且准确地处理。eĿlipsis不仅注重功能上的创新,更体现了在工程实现上的严苛标准。整个项目规模约三万行代码,充分利用C23语言的特性来保证代码质量和性能表现。
通过这样的实践,eĿlipsis已经在一个中等规模项目中验证了其新功能的实用性和稳定性。这些特性使得eĿlipsis不仅是一个实验性的预处理器,更是一个具备实际应用价值和发展潜力的工具。此外,eĿlipsis的文档体系虽然尚未完全完善,但用户已经可以方便地通过官方网站和代码仓库获取到详细的使用说明、支持语言范畴、预处理器扩展机制以及项目编译配置等丰富信息。其源码托管在Codeberg平台,用户可以使用git工具轻松克隆项目源代码,跟踪最新更新和提交。同时,开发团队积极维护的issue追踪器确保社区能够及时反馈和解决问题,促进项目持续健康发展。从技术角度看,eĿlipsis预处理器所带来的最显著优势是实现了真正的语言独立性。
传统的预处理器往往与某种特定语言深度捆绑,使得在其他语言环境下使用时往往产生兼容性和灵活性不足的问题。而eĿlipsis通过定义一套通用而完整的规范,避免依赖于特定语言的语法细节,使其可以灵活地服务于不同编程语言和文本数据处理需求。举例来说,对于需要同时处理C语言源代码和HTML文档的项目,传统预处理手段往往需要分别使用不同的工具进行文本转换和宏替换,而eĿlipsis则可以在同一个预处理过程中结合两者的特性,大幅简化工作流程,提高开发效率。此外,eĿlipsis还有望在未来逐步融入C和C++语言的标准预处理中,成为官方预处理器功能的有力补充,借助其现代设计和跨语言能力继续推动预处理技术的发展。对于开发者而言,采用eĿlipsis不仅能够享受到更灵活的源码预处理能力,还能够借助其Unicode支持处理国际化内容,提高代码对多语种环境的适应性。同时,利用项目本身作为中等规模的示例,开发者可以深入了解如何利用eĿlipsis的新扩展功能,积累实际运用经验。
总体来看,eĿlipsis展示了预处理器技术的重要发展趋势,即从语言专用向语言无关,从单一文本操作向多语言多场景支持的转变。在未来多语言共存、文本数据大量交互的技术背景下,类似eĿlipsis这样的工具无疑将发挥越来越关键的作用。通过不断完善和推广,eĿlipsis不仅能提升技术语言的处理效率,还能促进开发实践的创新与合作。对于关注编译原理、程序语言设计以及文本处理领域的技术人员而言,深入剖析和应用eĿlipsis将带来极具价值的技术积累和视野扩展。作为未来技术工具链建设的重要一环,eĿlipsis值得所有软件开发者、技术爱好者和研究人员密切关注。