随着人工智能技术的迅猛发展,语义理解和信息检索技术的要求越来越高。文本嵌入模型作为连接自然语言与计算机理解的桥梁,在众多应用中扮演着不可或缺的角色。EmbeddingGemma作为一款领先的开源嵌入模型,以其小巧、高效且性能卓越的特性,正在引领一场设备端AI领域的革命。EmbeddingGemma由Google DeepMind打造,专注于在本地设备上实现高质量的文本嵌入生成,助力开发者构建低延迟且隐私安全的智能应用。EmbeddingGemma体积仅有3亿零八百万参数,相较于其他流行模型,其参数量几乎减少了一半,却在多语言、多任务下展现出顶级的理解与表现能力。这不仅降低了运行时对内存和计算资源的需求,还使模型能够在手机、笔记本和各种边缘设备上高效运行。
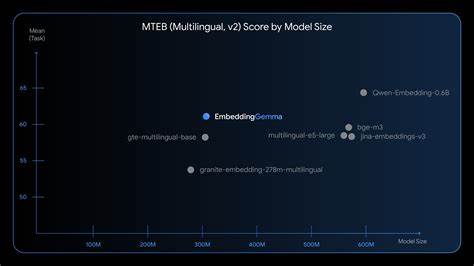
EmbeddingGemma在多语言嵌入生成任务中的卓越表现,已经通过权威的Massive Text Embedding Benchmark(MTEB)得到了验证,是目前500M参数以下开放模型中的佼佼者。它覆盖了100多种语言,支持从768维到128维的多样化输出向量,方便根据实际需求进行灵活裁剪,实现速度与精度的动态平衡。这种对内存资源的极致优化得益于创新的Matryoshka Representation Learning(MRL)技术,使得单一模型可以输出多尺寸的嵌入向量,为不同使用场景提供了充分的适应性。为了保证在设备端的快速响应和流畅交互体验,EmbeddingGemma采用了量化感知训练(Quantization-Aware Training,QAT)技术,内存占用降至200MB以下,同时保持了模型的高精度和稳定性。测试显示,在面向EdgeTPU等硬件加速器时,EmbeddingGemma仅需短短15毫秒内即可完成256个输入token的嵌入推理,真正实现了实时级别的处理速度,极大增强了用户体验。EmbeddingGemma最具创新性的设计之一是其完全支持离线运行,无需依赖云端服务,使用户数据能够始终保存在本地,保障隐私安全。
这点在当下数据安全意识增强的时代背景下尤为重要,无论是进行个人文件搜索,还是离线智能聊天机器人,EmbeddingGemma都能确保信息只在用户设备内处理,不会被上传或泄露。凭借与先进的Gemma 3n生成模型无缝协作,EmbeddingGemma成为构建移动端检索增强生成(RAG)方案的理想选择。RAG技术通过先检索相关上下文,再结合生成模型生成自然且贴切的回答,有效提升了智能问答和人机交互的准确度。EmbeddingGemma负责对用户查询和庞大文档库的多样文本进行高质量语义向量化,通过计算向量间相似度甄选出最相关内容,为后续生成模型提供坚实的语义基础。再配合Gemma 3n,整个流程既快速又隐私友好,能够满足移动设备处理复杂任务的需求。EmbeddingGemma同样保持良好的生态兼容性,现已支持主流机器学习和开发框架,如sentence-transformers、llama.cpp、transformers.js、Weaviate、LangChain等,极大便利了开发者集成和二次开发。
模型权重可以通过Hugging Face、Kaggle和Vertex AI等开放平台下载,配套文档和示例代码覆盖从基础推理到领域微调的各个环节,为不同背景的开发者提供丰富的落地参考。EmbeddingGemma的推出标志着设备端AI进入了一个新的阶段。从过去的云端依赖到如今本地化智能,开发者和用户都能享受到更低延迟、更高隐私保障以及更强的自主控制权。尤其在个人隐私、行业定制化以及边缘计算不断融合的趋势下,EmbeddingGemma为构建更丰富且个性化的智能产品提供了技术保障。展望未来,EmbeddingGemma仍有广泛的成长空间。随着硬件性能提升和算法优化,其性能和精度有望进一步突破。
同时,期待社区与产业界能围绕该模型催生更多创新应用,包括个性化信息检索、语义分类、智能助理、知识管理工具等,为用户创造更贴心且高效的数字体验。总结来看,EmbeddingGemma凭借其领先的设计理念、卓越的多语言解析能力以及智能隐私保护机制,成为了当前最适合设备端使用的文本嵌入模型。它打破了性能与轻量化之间的传统矛盾,为移动端检索增强生成和语义搜索的广泛应用奠定了坚实基础。随着更多开发者拥抱EmbeddingGemma,未来的智能设备将拥有更敏锐的语义理解力、更便捷的交互方式以及更可靠的数据安全保障,真正实现AI技术向普惠方向的巨大进步。 。









