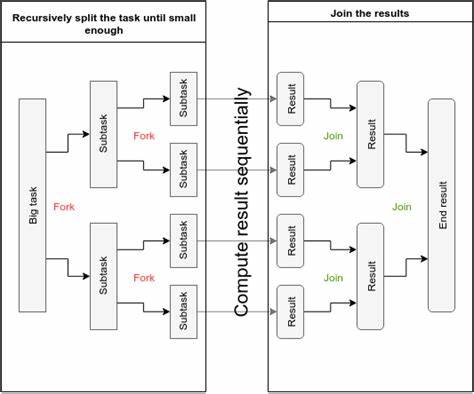
在当今高性能计算和多线程编程环境中,如何高效管理数据结构的状态复制和合并问题,始终是软件设计的重要挑战。传统的数据结构通常在更新时通过修改原地内存来完成,这虽然高效,但在多线程与并行场景中容易产生数据竞争和不一致。因此,如何既能充分利用共享内存的优势,又能保证数据的安全和一致性,成为研发者极其关注的重点。Fork-Join数据结构正是在这种背景下应运而生,融合了持久化和变异数据结构的优点,提出了具备“分叉”和“合并”能力的全新范式。持久化数据结构源自函数式编程理念,其核心思想是“不可变性”,即每一次“更新”操作并非修改本体,而是生成一份全新的数据副本,内部通过结构共享来避免完全复制带来的性能负担。其优势在于数据版本安全且线程友好,但随着数据规模的增长,复制操作仍可能带来不可忽视的性能瓶颈。
为了解决这一挑战,出现了“暂态数据结构”(transient structures),它们在接口上模仿持久化数据结构,允许内部进行原地变异以提升性能,但依然保持函数式编程中的易用抽象。暂态结构适合在性能敏感的代码段短暂使用,而后再转回不变数据结构,从而获得较好的折中。然而,现实中很多软件系统采用的编程范式并非完全函数式,而是在某种程度上容忍甚至鼓励变异。人们在设计数据结构时,也希望既享受变异带来的高性能,又希望具备在必要时进行快速复制和合并的能力。这便激发了Fork-Join数据结构的设计灵感。Fork-Join数据结构通过将“复制”(fork)与“合并”(join)操作显式纳入接口,允许用户在变异和不变之间灵活切换,同时利用持久化数据结构的结构共享机制,实现子线性级别的复制成本与高效的版本合并。
它拓展了传统暂态结构的概念,基于一种新的哲学:承认变异的存在和必要性,但不放弃数据副本的独立性和性能优势。具体到应用层面,当系统需要将数据结构传递给不同线程或任务时,可以通过fork操作快速复制出独立版本,供各自进行变异,避免竞争和冲突。随后,所有子任务完成后,可以用join操作将这些独立版本高效合并,构建成一个统一且最新的状态。这种设计非常适合数据并行编程,如MapReduce、图计算、金融模拟和大规模数据处理等领域,有效保障了数据安全与并发性能。除了性能和线程安全上的好处,Fork-Join数据结构还缓解了开发复杂度。因为它的接口设计接近传统可变数据结构,使得开发者可以几乎无感地替换底层实现,无须对业务逻辑做出大规模改动。
这一点大大提升了新数据结构的采用门槛和可维护性。另一方面,借助于持久化数据结构的结构共享,Fork-Join机制不仅支持快速复制,还可以实现高效的版本合并操作。这一能力在多线程和分布式环境中尤为重要,可以减少状态同步的开销,提升整体系统吞吐量。当前,业界已有一些持久化列表、映射和集合类型的数据结构实现支持结构共享,未来随着Fork-Join思想的深入,预计会涌现出更多具备此类操作特性的通用数据结构库。此外,Fork-Join数据结构还为传统函数式与命令式编程范式架起了一座桥梁。函数式编程强调不可变性和无副作用,能够提供极佳的可推理性和测试便利性,而命令式编程则偏向直接操作和高性能。
Fork-Join机制在两者之间找到平衡点,在保证接口统一的同时,支持灵活的变异和效率优化,使得不同范式的代码能够共存且高效协作。理论上,基于Fork-Join的数据结构可以衍生出多种策略,如延迟复制、增量合并甚至冲突检测和解决,为未来的状态管理和同步机制提供强大支持。从技术实现角度来看,Fork-Join数据结构依赖高度优化的内部节点复用和递归合并策略。其内部设计通常采用树形结构,更新时通过路径复制产生新版本,并利用指针复用减少内存拷贝。合并操作则借助于两棵树的结构相似性,只在差异部分执行合并,避免了全量扫描和复制,显著提升效率。总体而言,Fork-Join数据结构代表了一种前沿且实用的设计趋势,适应了现代多核、多线程编程的需求。
它结合了持久化数据结构的安全性与暂态数据结构的灵活性,为复杂系统的数据管理带来了变革。随着多核处理器与分布式计算的普及,采用此类数据结构有望帮助开发者写出更高效、更健壮且易维护的程序。未来,与人工智能、大数据、云计算等领域的深度结合,将进一步催生全新模式的状态管理框架。整体来看,理解并应用Fork-Join数据结构,不仅能够提升程序性能,还将促进软件架构的现代化和模块化,成为开发者迈向高质量软件的有力工具。