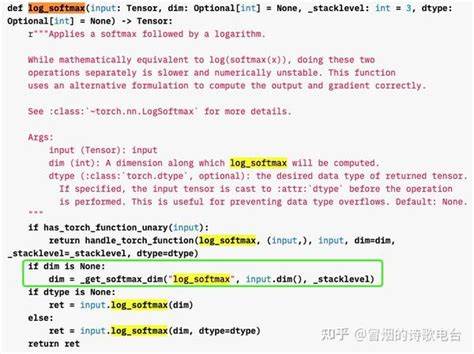
在现代数据科学领域,数值计算的稳定性成为一个极其重要的话题,尤其是在深度学习、概率模型以及统计推断等任务中,计算过程中的数值漂移和溢出风险常常影响到模型的准确性和实用性。SoftMax函数作为一种常见的归一化方法,经常被用来将原始得分转换为概率分布,广泛应用于分类和排名任务中。然而,SoftMax本身在面临带有极端值的数据时,极易产生数值不稳定问题,导致计算结果变得失真甚至无效。为了克服这个问题,LogSoftMax逐渐成为更加优选的解决方案,被众多数据科学家和工程师采纳。SoftMax函数其实来源于统计物理中的玻尔兹曼因子,最早被用来描述能量状态的概率分布。在数据科学环境中,给定一个向量,通过对其每个元素进行指数变换后,再除以所有指数值的和,就能得到元素的相对概率。
然而,指数函数的快速增长特性也带来了隐患——当向量中存在较大的值时,指数函数极易导致溢出,其他较小的分量由于分母变大而被近似为零,使得SoftMax输出极度偏倚。我们举一个极端的示例,设有一组得分[1.4, 1.5, 1.6, 170],其代表四个团队的表现指标。在常规SoftMax计算后,前三个队伍的概率几乎为零,而最大值170的队伍概率接近1。这样处理虽然直观,但缺失了对其他队伍细微差别的表达,严重影响排序和决策效果。这种情况下直接应用SoftMax会导致结果失真,无法很好地反映原始数据的结构。LogSoftMax通过先计算指数和的对数,用减法转换指数计算,可以避免指数函数直接应用对数值范围的过度扩大造成的溢出问题。
具体而言,它计算的是每个分量的对数概率,即log(exp(x_i))减去log(∑exp(x_j))。这样处理之后,不仅保留了数值的排序信息,也避免了大数值冲击导致的小数值过零问题。延用上述示例,[1.4, 1.5, 1.6, 170]经过LogSoftMax转换后,得到的结果大致是[-168.6, -168.5, -168.4, 0],可以明显看出排位顺序变得连续,分布更合理,避免了原先并列为零的尴尬。同时,由于结果在对数空间,适合后续的对数似然计算和优化算法,极大提升了数值计算的稳定性和准确度。LogSoftMax在机器学习框架中同样是权威支持的功能,像PyTorch、TensorFlow均提供了高效的实现接口,使得开发者在进行模型训练时能够简化数值控制问题。更值得注意的是,LogSoftMax不仅应用于分类任务,还在无监督学习、强化学习和概率模型中扮演关键角色,尤其对于大量元素的归一化问题表现尤佳。
统计领域也同样认同使用对数变换来稳定指数运算的观念。高斯分布等模型频繁涉及指数幂,直接运算往往带来数值不确定性,采用对数似然函数成为标准做法,确保分析结果的可信度和稳定性。总体来看,采用LogSoftMax替代SoftMax,不仅能避免归一化过程中指数溢出的风险,更能细致反映元素之间的相对关系,提供更加准确和稳定的概率估计。对于数据科学工作者而言,理解这一点有助于搭建稳健的计算路径,防止模型训练和推理时因数值过大或过小而导致的错误和崩溃。综上所述,虽然SoftMax作为概率归一化的经典方法仍然存在其应用场景,但从数值稳定性和精度控制角度出发,LogSoftMax无疑是更优的选择。在面对大规模及复杂数据集时,采用LogSoftMax不仅保证了计算的健壮性,同时优化了结果的解释性和模型表现。
随着数据科学技术的不断发展,加强数值稳定性意识、选择合适的函数变换方法,将为未来智能模型的精准化和可靠性提供坚实基础。