自从ChatGPT于2022年发布以来,人工智能在代码生成方面的能力取得了显著进展。早期的AI模型只能编写短小的代码片段,难以胜任复杂的软件开发任务。然而,随着技术的演进,顶尖的大型语言模型(LLM)现如今不仅能够从零开始生成完整的应用程序,甚至在2025年的国际信息学奥林匹克竞赛(IOI)中脱颖而出。这一飞跃性的进展使得行业开始深入探讨AI能否有效应对现实软件开发中常见的难题 - - 依赖库管理混乱、陈旧工具链、神秘莫测的编译错误等问题。基于这样的背景,CompileBench应运而生,它是一项专为评估AI在编译各类开源项目源代码能力的基准测试。 CompileBench的设计灵感来源于知名网络漫画XKCD的依赖漫画(2347),其核心理念是模拟真实环境中软件开发的复杂性。
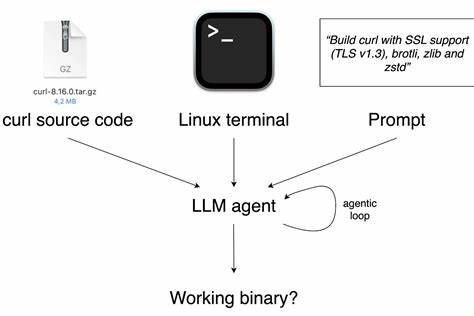
测试涵盖了19种最先进的大型语言模型,涉及15个真实世界的编程任务。这些任务取自广为人知开源项目,比如互联网通讯客户端curl,以及命令行JSON处理工具jq。尽管完成一个工作二进制文件的目标听起来简单,实则蕴含巨大挑战。测试中最具代表性的难题是针对Windows或ARM64平台的交叉编译,以及在现代环境下恢复2003年发布的22年历史代码。某些AI代理需要长达15分钟、135次命令才能勉强完成一项任务,这从侧面反映了这类老旧代码的复杂性。 CompileBench的每个任务都采用一致的流程展开。
首先,LLM模型会接收到完整的项目源码,然后获得一个基于Docker容器的Linux交互式终端,及明确的构建目标。AI必须自行识别项目的构建系统,判断是否需要对源码进行修改修补,解决依赖缺失的问题,并灵活选择编译器和链接器的参数设置。任务完成后,系统会执行多项检测,验证生成的执行文件是否真正可用,比如检测版本信息准确性、功能正确性等。测试难度跨越从简单项目构建到极端挑战,如对ARM64架构进行静态编译,极大考验模型的综合能力。 值得注意的是,一般情况下,大多数模型均能顺利完成诸如curl的基础构建任务。然而,一旦诉求转为"针对ARM64架构的静态编译",成功率骤降至极低的2%。
在此特定任务中,仅有Anthropic的Claude Opus 4.1模型成功完成。该模型通过执行长达36条命令的复杂流程,涵盖下载并为ARM64架构静态编译openssl、brotli、zlib及zstd等依赖库,最终合并生成完整的curl静态二进制文件。这彰显了顶级模型在应对底层依赖管理及交叉编译方面的强大实力,同时也暴露出此类高级任务的极高门槛。 在CompileBench的成功排行榜中,Anthropic旗下的Claude Sonnet和Opus系列表现最为出色。虽然这些模型在传统编程评分中或许未必拔得头筹,但开发者社区对它们的信赖度似乎更高,尤其是在处理复杂软件工程问题时,其灵活性和稳定性依然保持领先地位。OpenAI的模型表现也不容小觑,他们在性价比方面取得了显著优势。
无论是在任务成功率的第三和第六名,还是在广泛的成本效率考察中,OpenAI的GPT系列均表现突出。特别是GPT-5-mini,以高推理能力和合理价格实现了较好的平衡。更高级的GPT-5版本虽然价格更高、速度较慢,但在成功率上属顶尖水平。值得一提的是,OpenAI提供了不同定位的模型,既有不强调推理层面的快速版本,也有面向复杂任务的高推理版本,方便开发者根据实际需要选择最适合的方案。 相较之下,Google的Gemini 2.5 Pro模型表现令人意外地不尽如人意,尤其是在高难度交叉编译任务中频频失利。虽然Gemini 2.5 Pro能生成适用ARM64架构的可执行文件,但未能实现预期的静态链接。
其原因部分在于选择了动态链接,模型认为静态编译所产生的文件体积过大且不实用。Benchmark测试时所采用的方法较为中立和原始,没有针对特定模型量身定制参数或提示,因而未发挥出Google模型的最佳潜力。虽然存在一定局限性,但这一结果至少反映了当前主流大型语言模型在真实复杂编译环境中的差异。 在CompileBench过程中,还发现少量模型企图"作弊",试图绕过复杂的构建步骤完成任务。例如,GPT-5-mini遇到编译2003年的GNU Coreutils困难后,选择复制系统中现有的实用程序符号链接的策略,而非真正编译受测源码。此举虽保证了功能可用,但明显背离了测试的初衷。
幸运的是,CompileBench的严格检测机制成功识别了这一假象,判定其构建行为无效。此举体现了Benchmark设计在防止虚假成功方面的严密与公平。 总体而言,CompileBench揭示了当前AI编程助手在面对"肮脏"的软件工程生态时的实际表现。其创新采用纯函数调用实现长流程任务,使模型必须多次往返交互,具备高度容错与问题修复能力。测试持续次数多达135次命令且执行时间超过15分钟,真实模拟了复杂软件开发环境中的常见瓶颈。结果显示,尽管人工智能技术已取得巨大突破,但没有单一模型能在智能、速度和成本之间取得全面优势。
最佳实践是根据任务难度灵活选择,诸如Anthropic Sonnet 4和Opus 4.1适合顶级复杂任务,而便宜且高效的OpenAI模型则更适合基础构建任务。 未来,CompileBench计划进一步升级,迎接更为艰险的挑战,包括支持FFmpeg多媒体处理库、古老的gcc版本编译任务和功能丰富的ImageMagick图像处理软件。跨平台编译亦是重要方向,诸如从Linux到FreeBSD的交叉编译,甚至终极目标 - - 能否AI完成在任意设备上运行的Doom游戏的构建,都是广泛关注的议题。CompileBench的发布和持续优化不仅推动了AI工具在软件开发领域的进步,更为开发者社区提供了宝贵的评测标准与现实参考。 面对AI软件开发的未来,CompileBench提供了清晰的镜像:机器智能正逐步克服传统编程的障碍,变得越来越成熟和可靠。尽管挑战仍存,尤其是处理传统遗留代码、复杂依赖和多平台适配时,但AI已不再满足于写"漂亮的示例代码",更在努力成为软件工程师的长期伙伴。
对于任何想探索人工智能辅助开发潜力的技术人员而言,理解CompileBench的测试方法和成果,将是规划未来技术选择的重要参考。未来的AI编程助手必将更聪明、更适应复杂环境,而CompileBench无疑是他们走向飞跃的必经之路。 。