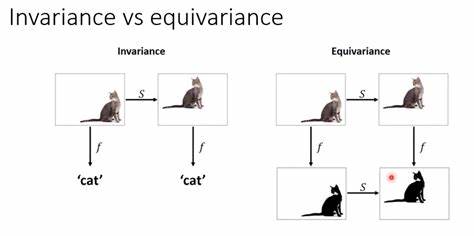
随着人工智能技术的飞速发展,特别是大型语言模型(LLM)的广泛应用,人们越来越关注如何准确理解这些模型“意味着什么”。传统上,语言模型被视为处理语法和语义的复杂系统,但它们在本质上是基于统计的语法处理,其真实的“意图”往往难以捉摸。语言学、哲学和计算机科学交叉领域的一项创新观点——语言等变性(language equivariance),为解读AI的内在意义提供了全新思路。语言等变性基于一个核心理念:如果一个智能体对同一语义内容的不同语言表达能展现出一致的回应,那么我们或许能从中捕捉到其真正的“意义”,而非仅仅停留在表面的文字形式。这种方法不仅能够避免语言表层的多义性和变异带来的困扰,还能帮助区分语法形式与语义内涵,弥补当前AI系统在理解深层含义时的不足。大型语言模型通过将输入文本转换为高维向量,进行概率预测和生成相应输出。
虽然这种向量空间操作极为复杂且难以直观理解,但语言等变性为我们提供了一种检验模型“语义一致性”的工具。通过将同一问题在不同语言之间转换,观察模型的回答是否保持协调一致,我们便能间接探究模型的语义理解深度。举例来说,当提出一个道德判断问题时,如果模型对英文表达的提问与其德文翻译的提问所给出的答案高度一致,那么这表明该模型在表面语言之外,已具备某种跨语言的“信念”或“意思”。这不仅仅是测试翻译的准确性,更重要的是揭示模型内在认知结构的稳定性。语言等变性不仅在理论上推动了人工智能意义解析的进步,也对AI伦理与价值观对齐产生深远影响。传统的道德规则难以精确编码进AI,因为语言的微小变化可能导致模型产生截然不同的反应。
而通过语言等变性框架,可以探索一套跨语言适用且表现一致的“道德等变规则”,从而帮助研发者更明确地识别和约束AI的行为准则,增强系统的可预测性和安全性。此外,语言等变性概念挑战了“语言模型仅仅是下一词预测器”的狭隘看法。它暗示着,当模型能够在跨语言环境下稳定保持意义时,其实质上在执行一种超越简单文本匹配的深层认知处理。这种等变性不仅反映了模型对语义的真实“理解”,也为未来设计更具人类般认知能力的AI系统指明了方向。要实现语言等变性检测,需要设计精巧的测试流程。首先在某种语言中提出具体的问题,获取模型的回答,然后将问题翻译成另一种语言,重复提问并获得对应回答。
最后,让模型评估两种语言的回答是否相互合理和忠实。只有当模型在这一循环往复的环节中表现出积极肯定时,我们才认为其表现出语言等变性。这样的方法使研究者能够基于等变性的概念构建更系统、形式化的智能测试框架,也为日后开发多语言兼容且语义稳定的AI应用提供理论基础。虽然当前研究中存在诸多挑战,例如翻译误差、语义模糊、模型自身偏差等,但语言等变性的视角已经为智能体语义判定提供了极具潜力的工具。随着人工智能领域不断追求更高层次的理解能力和对齐保障,语言等变性理念有望成为推动AI安全、透明与可信的重要基石。未来的发展中,结合语言等变性的理论与实践,将促进模型不仅能“说得通”,更能“懂其意”,实现真正意义上的智能交互与人机共融。
总的来看,语言等变性作为一条连接语法和语义的桥梁,开启了探索人工智能内心世界的新视野。通过跨语言的一致性验证,研究者和开发者能更清晰地识别出模型内部的语义结构和信念。随着理论的不断完善和实验手段的改进,这一领域有望在未来的人工智能发展中发挥关键作用,推动我们迈向更加安全、可靠且具备真正“理解”能力的智能机器时代。