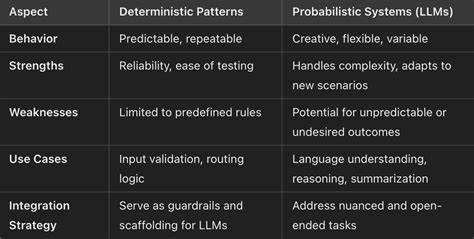
引言 随着软件安全的重要性不断上升,自动化的代码审查工具已成为开发和安全团队不可或缺的组成部分。近几年大型语言模型(LLM)在代码理解和生成方面的能力突飞猛进,催生了基于LLM的代码审查服务。与此同时,传统的确定性静态应用安全测试工具(SAST)仍然在企业合规和静态分析领域占据主导地位。面对这两类截然不同但具有互补优势的技术,安全团队需要了解它们的本质差异、适用场景以及如何将两者整合以实现更高效、更可靠的安全检测与漏洞管理。 什么是LLM代码审查和确定性SAST工具 LLM代码审查基于预训练的大型语言模型,利用自然语言理解和代码建模能力对提交的代码进行安全性、质量和风格方面的建议。它可以识别常见的安全错误模式、潜在的逻辑缺陷、注入风险等,输出可读性强、带有解释的建议,甚至给出修复示例。
确定性SAST工具则依赖符号执行、抽象语法树(AST)分析、数据流跟踪和模式匹配等传统静态分析技术,基于明确规则和扫描器插件来检测代码中的安全漏洞。其结果通常具备严格的可追溯性和确定性,便于在合规审计和报告中使用。 检测能力与覆盖范围的对比 LLM代码审查擅长基于语义的推理,能够在跨文件、跨模块的上下文中理解业务逻辑,从而发现那些并非简单模式匹配可判定的问题。对于复杂的输入验证缺失、逻辑错误、边界条件、权限绕过等场景,LLM往往能产出高质量的诊断和修复建议。另一个优势是对项目特定惯例、注释和文档的理解,使其建议更贴合业务实际。确定性SAST工具在低层次安全缺陷检测上具备稳定性和高覆盖率,尤其在内存安全、命令注入、路径遍历、资源泄露等明确可表述的漏洞模式上表现可靠。
它们在规则库、合规映射和可审计输出方面具有优势,适合监管要求较高的场景。 误报与漏报的权衡 误报(false positive)和漏报(false negative)是任何自动化检测工具面临的核心问题。确定性SAST因基于显式规则和静态约束,容易在复杂代码路径上产生误报,尤其是当规则无法理解项目特定的上下文时。许多组织通过规则调优、白名单和配置文件来降低误报率,但代价是需要维护投入。LLM的误报形态更为多样,既可能提出合理但不必要的改动建议,也可能对真实漏洞给出置信度不足或错误的解释。其漏报往往源于模型对特定语言细节或第三方库行为理解不足。
与传统工具不同,LLM通常给出自然语言解释,这有助于分析人员快速判断真伪,但也可能误导不具备安全背景的开发者。 可解释性与可审计性 企业安全治理和合规审计要求工具输出可追溯、可复现的证据链。确定性SAST工具的分析过程和规则通常是透明且可复现的,分析报告包含漏洞位置、触发规则、可复现路径等关键信息,便于记录与合规审计。LLM代码审查在可解释性方面存在挑战,模型内部的推理过程并不透明,输出的解释更多依赖自然语言表达。尽管可以通过提示工程要求模型给出检测依据和代码路径,但这些依据并非以确定性逻辑链条存在,难以在审计场景中替代传统工具。然而,LLM优质的自然语言解释可以显著提升开发者理解漏洞根本原因的效率,从而缩短修复时间。
集成与开发流程适配 从DevSecOps角度看,工具的易集成性和对开发流程的侵入程度决定其实际价值。确定性SAST工具通常提供CI/CD插件、命令行扫描和企业级管理平台,能无缝接入现有管线,支持批量扫描和集中管理。它们在扫描策略、扫描窗口和报告频次上有可配置性,适合大规模静态扫描。LLM代码审查工具则更灵活,可作为IDE插件、Pull Request助手或聊天式助手出现,提供实时反馈和修复建议。其即时交互性有利于在开发早期发现问题,减少后期修复成本。最佳实践是将LLM用于早期交互式审查和开发者教育,将确定性SAST用于关键版本发布前的全面扫描和合规检查。
安全与隐私风险 LLM系统在处理敏感代码时涉及潜在的数据泄露和模型滥用风险。将未脱敏的源代码发送到第三方LLM服务可能触及知识产权和合规边界。企业需要评估模型托管方式,优先选择本地部署或受控的私有云模型,并采用数据最小化和脱敏策略。传统SAST工具通常在本地或受控环境中运行,安全边界更加明确。对LLM的调用需要严格的访问控制、日志审计和数据使用策略,以避免将企业敏感信息外泄给模型提供商或成为训练数据的一部分。 性能与可扩展性考量 确定性SAST工具在大规模代码库上的批量扫描策略已经非常成熟,能有效利用并行处理和缓存机制来缩短扫描时间。
LLM基于复杂的推理计算,尤其在模型规模较大或需要跨文件深度分析时,计算资源和延迟成本较高。为保持开发者体验,LLM审查系统常采用增量分析、缓存最近上下文或混合规则引擎来提升响应速度。企业在评估时应考虑扫描频率、延迟接受度与成本预算,找到性能与准确性的平衡点。 合规与治理的现实需求 在受监管行业,合规检查往往要求可复现的分析链路和明确的漏洞分类映射。确定性SAST工具在生成可审计报告、支持CVSS评分和法规条款映射方面具有先天优势。LLM可以补充上下文分析、生成更具可读性的修复建议以及帮助编写安全文档,但难以单独满足审计证据的需要。
合规策略应将LLM产出视为辅助证据,搭配确定性扫描的正式报告一起提交,或在SAST扫描后用LLM生成可理解的补充说明以提高审计效率。 成本与人员能力投资 引入任一类工具都需要考虑许可成本、基础设施和人员培训。确定性SAST工具的长期许可和规则维护成本不容忽视,但其稳定的输出与合规属性让高投入有明确回报。LLM工具的成本结构以调用次数或部署资源为主,若选择自托管大模型还需显著的硬件投入。与此同时,组织需要培养具备模型提示工程、安全背景和开发经验的复合型人才,以充分发挥LLM的价值。结合两者往往要求跨职能团队协作,建立反馈循环以不断调优规则和模型提示。
如何评估和选择 评估工具时应以风险驱动的方法为主。首先明确目标:是提高开发阶段的快速反馈,还是满足发布前的合规扫描?若目标偏向实时反馈与开发者教育,优先考虑LLM代码审查作为首选。若目标是生成可审计报告、满足法规要求或对低级别漏洞进行准确检测,确定性SAST工具更适合。评估指标应包括检测覆盖率、误报率、漏报率、可解释性、集成成本、隐私与合规风险、性能和维护负担。建议通过试点与A/B测试在真实代码库中衡量实际效果,而不是仅凭厂商的演示结果做决策。 混合策略的实践路径 最佳实践往往不是选边站队,而是将LLM与确定性SAST工具组合成互补体系。
在持续集成中将确定性SAST作为门控扫描,保证关键里程碑的合规性与基础漏洞检测。同时在开发者侧提供LLM驱动的IDE插件或Pull Request助手,用于快速发现逻辑错误和给出修复建议。对于SAST报告中标注难以理解或优先级分散的告警,可以通过LLM生成可读性更高的摘要和修复优先级评估,帮助安全工程师和开发者更高效地处理告警。建立反馈回路,将开发者的处理结果反向用于微调SAST规则和LLM提示,有助于长期降低误报并提升整体检测质量。 组织采用与文化变革 技术只是一部分,流程与文化的调整同样重要。组织应强化早期安全介入,将工具嵌入到开发生命周期的早期环节,鼓励开发者在提交阶段自行解决可解决的问题。
提供明确的告警分级、处理SLA和知识库,结合LLM生成的解释性内容提升培训效率。安全团队应从单纯的告警发出者转变为流程协调者,负责工具链的调优与策略制定,确保技术投入带来实际的安全改进。 未来趋势与技术展望 未来几年可以期待更多面向代码安全的专用大模型出现,它们在隐私保护、自我解释和符号推理方面会有改进。模型与确定性分析技术的结合会越来越紧密,出现混合推理引擎,将符号执行与统计推理共同用于漏洞检测与证据生成。企业级解决方案会更加注重模型可控性、本地化部署和可审计性,满足监管要求。与此同时,自动化漏洞修复建议和安全知识库的闭环更新将使得工具对开发者的辅助能力持续增强。
结论与建议 LLM代码审查与确定性SAST工具各有优势与限制,关键在于理解其适用场景并构建互补的使用策略。将LLM用于开发阶段的语义审查和修复建议,可以大幅提升开发者效率和问题修复速度;将确定性SAST作为发布前的合规与基础漏洞检测,保证可审计性和稳定的覆盖。优先在试点中评估两类工具的检测效果与工作流影响,通过反馈循环不断调优。重视数据隐私与合规风险,优先选择支持本地部署或受控托管的解决方案。最终,通过技术、流程和文化的协同提升,才能在实际生产环境中实现可衡量的安全价值,并在动态威胁环境下保持敏捷与可信赖的安全保障。 。