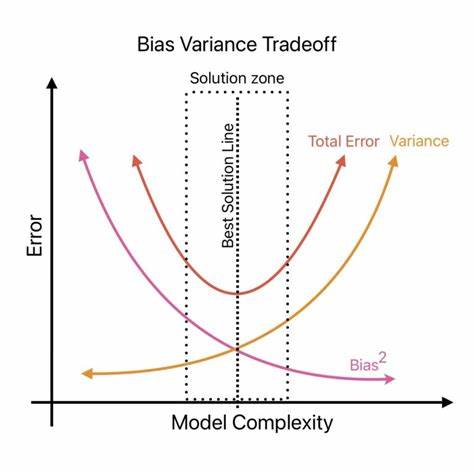
在机器学习和统计学领域,偏差-方差权衡长期以来被视为理解模型性能和优化的基石。该理论认为,模型复杂度的提升会减少偏差,但同时增加方差,反之亦然。理想状态下,应在偏差和方差之间找到一个平衡点,使模型不仅能拟合训练数据,又能在未见数据上表现良好。然而,近年来越来越多的研究和实践结果表明,偏差-方差权衡的传统解读存在诸多不足,甚至在某些情境下可能误导模型设计和优化的方向。本文将从多个层面剖析偏差-方差权衡的局限,并介绍现阶段更为前沿的理论和方法,帮助读者构建更准确的模型认知。偏差和方差的经典定义虽然在统计学基础上清晰明了,但现实中的机器学习任务远比理论模型复杂得多。
例如,深度神经网络等复杂模型具有惊人的拟合能力,能够在巨大参数空间中同时优化训练误差,直至几乎为零,此时传统的偏差-方差权衡难以解释为何这些模型仍能在测试集上保持较好的泛化性能。进一步而言,所谓的"过拟合"与"欠拟合"边界在实证中显得模糊。某些情况下,提升模型复杂度不仅没有显著增加方差,反而改善了泛化效果,这与偏差-方差权衡中复杂度提升必然带来方差升高的观点相悖。这种现象促使研究者反思,是否需要重新定义方差?或者考虑模型内的其他机制,比如优化算法和隐式正则化的影响。近年来的理论进展尝试解释深度学习模型为何在过参数化条件下依然保持良好泛化能力,指出传统偏差-方差分解忽视了模型训练过程中的细节和数据结构特征。例如,隐式正则化描述了优化算法(如随机梯度下降)隐含的偏向性,能够引导模型向更简洁的解空间移动,从而抑制方差的泛滥。
此外,高维数据的本质也不同于低维统计问题,数据几何结构、训练样本分布的复杂性,使得偏差和方差的传统衡量方式难以全面捕捉模型行为的多样性。机器学习领域对偏差-方差权衡的质疑还带来了更加注重模型复杂性之外因素的思考,如训练数据的质量与数量、噪声水平、以及模型设计中的架构选择等。合理的数据增强、正则化策略以及优化参数的调节,都可能打破传统的偏差-方差框架限制,从实际表现上提升模型性能,而不必严格遵循降低偏差必然提高方差的经典理念。除了理论层面对偏差-方差权衡的挑战,实践者也在不断探索更灵活、更适用的评估方式。诸如泛化误差的直接估计、通过交叉验证和贝叶斯推断整合不确定性评判,都在一定程度上避免依赖简化的误差分解模型。特别是在工业界,模型实际应用中更关心的是稳健性和可解释性,这也促使机器学习工程师们超越传统观点,考虑全面多样的设计与评估指标。
总结来说,偏差-方差权衡作为经典理论给机器学习的发展做出了巨大贡献,提供了初步理解模型选择与优化的框架。然而,随着大规模复杂模型和高维数据时代的到来,单纯依赖这一框架显然不足以全面解释模型行为和性能表现。通过结合现代优化理论、数据几何分析及隐式正则化等多维度因素,机器学习领域正迈向更加丰富和准确的模型理解视角。未来,研究者和实践者应减少对偏差-方差权衡的盲目依赖,拥抱复杂模型和数据特征带来的新挑战和机遇,从而设计出更具鲁棒性和泛化能力的智能系统。 。