近年来,眼科医疗领域迎来了一场由人工智能驱动的革命,尤其是基础模型(foundation model)的出现,为眼科疾病的检测、诊断与管理带来了前所未有的机遇。EyeFM作为全球首个专注于眼科的多模态视觉-语言基础模型,因结合了多种成像技术与临床文本信息,成为智能辅助临床诊断的典范。该模型的开发和临床验证不仅提升了医生的诊断准确性,也在患者治疗依从性和临床报告标准化方面实现了显著进步,代表了未来智能医疗的重要发展方向。EyeFM的设计理念基于深度学习与视觉语言融合技术,它通过14.5百万张涵盖五种眼科影像模态的标注数据进行预训练,数据源涵盖全球多个国家和多种族群体,确保模型的广泛适用性和兼容性。成像类型包括彩色眼底照片、光学相干断层扫描(OCT)、外眼照片等,此外,模型还能够处理与影像相关的临床文本信息,如检查报告和病历描述。这种视觉与语言的多模态联合训练,使其在多任务诊断中表现出强大的通用性和精准度。
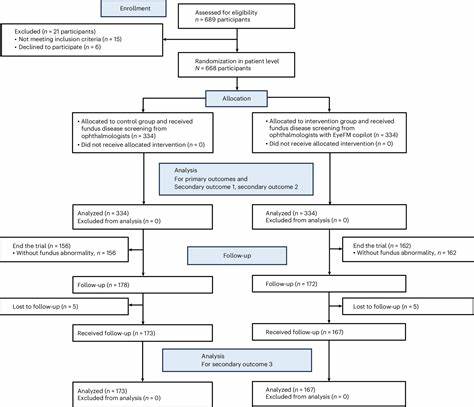
临床验证阶段,研究团队邀请了来自北美、欧洲、亚洲及非洲的44位眼科专家,在包括初级和专科医疗机构的多种临床环境中测试EyeFM的实际应用效果。随机对照试验(RCT)在中国高危人群中开展,涵盖668名平均年龄57.5岁的患者,分配到使用EyeFM辅助的医生组和传统诊疗组。在主要终点指标方面,辅以EyeFM的医生组表现出远超传统模式的正确诊断率(92.2%相较于75.4%)和转诊率(92.2%对比80.5%),表明模型显著提升了临床决策的准确性和有效性。其次,临床报告的标准化评分也被显著提升,反映出EyeFM在辅助医疗文书书写的能力,促进了医疗信息的规范化和可追溯性。患者方面,接受EyeFM辅助诊断的组别,在随访期间显示出更高的自我管理和转诊依从率,具体数值分别为70.1%与49.1%,以及33.7%对比20.2%,这展示了人工智能技术不仅助力医生,也积极影响并改善了患者的健康行为。技术架构上,EyeFM结合了24层Transformer结构的图像编码器,和基于LLaMA 2的7亿参数语言模块,通过一个线性投影层连接视觉和语言信息,实现了跨模态信息的深度融合。
光学成像的多解码器设计加强了对不同图像模态特征的提取能力,而人类专家知识的编码融入,使得模型在识别复杂眼疾时具备更强的临床专业判断力。此外,采用了包括直接偏好优化(DPO)和联邦学习等技术,保障了模型在多中心分布式数据环境下的安全性和持续学习能力,推动了知识的动态演变。EyeFM的构建和验证过程充分体现了人工智能在临床实践中落地的必要步骤和挑战。首先,模型必须经过严格的回顾性验证,以此确认其基础性能和安全性,在此基础上开展多国读者研究,观察其作为临床助手的适应性和实际效果。随后通过高标准的随机对照试验全面评估模型介入后对医疗结果的影响,确保其科学效益的可靠性和可推广性。这一系列验证流程为其他医疗AI项目提供了宝贵的范例。
在全球范围内,眼科疾病发病率持续攀升,尤其是糖尿病视网膜病变、年龄相关性黄斑变性和青光眼等慢性眼病,给公共健康系统带来了沉重负担。EyeFM的诞生恰逢其时,依托先进的深度学习模型,为早期筛查和精准诊断提供了有效工具,有望大幅缓解专业眼科医生资源不足的矛盾,推动分级诊疗和远程医疗的发展,提升医疗服务的可及性和公平性。尤其在资源相对匮乏的地区,通过低成本影像设备结合EyeFM辅助诊断,可实现疾病的快速识别和及时转诊,保障患者获得更优质的医疗服务。除了诊断支持,EyeFM在人文关怀层面也表现出极大潜力。其报告编写和视觉问答功能不仅提高了文书写作的效率和质量,也兼顾了医患沟通的需求,生成的专科医生指导文本在准确性、安全性及同理心上均达到高标准,助力构建更具温度的医疗服务体系。用户的高度接受度和满意度进一步印证了该模型在临床环境中应用的可行性。
展望未来,融合基础模型的视网膜疾病智能辅助诊疗将成为眼科的新常态。研发团队计划继续扩大模型的多模态能力,涵盖更多影像类型、临床检查及基因组数据,提升对罕见病和复杂病例的识别力。同时,将通过持续更新和人机协同学习机制,增强模型的自我进化与个性化方案推荐功能。伴随着医疗AI伦理、隐私保护和法规体系的不断完善,EyeFM有望成为全球眼科医生不可或缺的智能助理。总的来看,EyeFM的成功不仅是一项技术突破,更是医疗智能化进程中的重要里程碑。它以海量多元数据为支撑,结合视觉语言双重智能,系统化优化了眼科诊疗全流程,提升诊断精准度、改善患者管理,并为临床决策提供科学依据。
这一创新模式有效连接了科技与临床的桥梁,为推动普惠健康、实现智慧医疗打下坚实基础。随着人工智能技术日趋成熟,EyeFM及其后继者将进一步释放潜力,开启人类视觉健康保护的新纪元。 。