在众多面试题与工程问题中,求数组的第三大元素看起来既简单又富有延展性。表面上可用排序、堆或选择算法解决,但深入实现细节后,会发现现代 CPU 的内存层次、分支预测以及 SIMD(单指令多数据)向量指令对性能有巨大影响。本文从问题建模出发,分析传统标量解法的特征,进而介绍一种基于 AVX2 的 SIMD 优化策略,讨论实现细节、几种变体、性能基准与工程折衷,并给出可供实际工程采纳的建议。 问题本质与常见解法的性能特征 寻找数组的第三大元素可用多种策略实现。直接排序是最直观的做法,时间复杂度 O(n log n),实现简单且对常数项优化友好。利用大小为 k 的最小堆可以把复杂度降到 O(n log k),对大 n 且小 k 非常有效。
C++ STL 的 nth_element 使用部分排序思想,平均线性时间但具有较大常数项且对输入分布敏感。对于 k 很小的情况,尤其是 k=3,手写的三个元素维护逻辑或插入排序的微型实现在实际运行中常常胜出,因为数据局部性好,分支预测命中率高,且内存访问仅限于栈上的少量变量。 尽管如此,标量实现有一个共同的限制:单个元素的比较和移动是顺序的。随着 SIMD 的普及,能否在寄存器层面并行比较、并行查找插入位置并一次性更新 top-k 数组,从而把插入步骤的时间从依赖 k 的循环降到常数时间,是一个值得探索的方向。对于 k<=8,AVX2 的 256-bit 寄存器或 SSE 的 128-bit 寄存器都能恰好容纳若干个 int32,同样的思想也能扩展到 AVX512 来支撑更大的 k。 用 SIMD 在寄存器里维护 top-k 核心思路是把当前的 top-k(按从大到小或从小到大排序)保存在一个 SIMD 寄存器中,把候选值广播到寄存器每个 lane,比较得到按位掩码,然后用掩码和移位、混合(blend)指令完成插入操作。
以 SSE 的 128-bit 寄存器为例,可以用四个 int32 表示 maxSoFar。当有一个新值 x 到来时,先用广播把 x 放满寄存器,然后用比较指令得到每个 lane 是否小于 x(或者相反的比较,视表示方式而定)。接下来用逻辑与移位操作生成一个插入掩码,最后用 blend 指令先把寄存器按需右移一位以腾出位置,然后把 x 条件性地写入正确的 lane。 实现要点之一是移位函数的字节级参数特性:_mm_srli_si128 的立即数以字节为单位,且在 256-bit 下的对应指令会在上下半区分别执行独立移位,这在设计多寄存器实现时需要特别注意。使用的关键向量指令包括广播、比较、按字节移位、按字节混合(blendv)以及按位异或(xor)等。以 SSE/AVX2 intrinsics 为例,伪代码样例如下: inline void insertNewMax_x4(__m128i &v_maxSoFar, __m128i x) { __m128i v_cmplt = _mm_cmplt_epi32(v_maxSoFar, x); __m128i v_insertion_mask = _mm_xor_si128(v_cmplt, _mm_srli_si128(v_cmplt, 4)); __m128i v_shift1 = _mm_srli_si128(v_maxSoFar, 4); v_maxSoFar = _mm_blendv_epi8(v_maxSoFar, v_shift1, v_cmplt); v_maxSoFar = _mm_blendv_epi8(v_maxSoFar, x, v_insertion_mask); } 这段逻辑的含义是:先比较得到哪些 lane 小于 x,然后通过右移和 XOR 操作定位插入点的掩码,再用 blend 把需要右移的 lane 覆盖为右移后的值,最后把 x 写入对应的插槽。
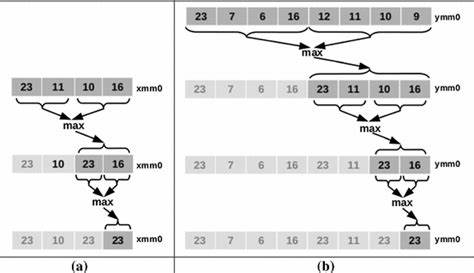
整个插入操作是常数条向量指令完成的,不需要按 k 循环比较或移动,因此对小 k 而言理论上非常高效。 扩展到 AVX2 与八向量并行扫描 将寄存器规模提升到 AVX2 可支持的 256-bit,意味着单个寄存器可以容纳 8 个 int32。这给一个有趣的机会:除了对单个候选元素进行插入,可以对输入数组做"预读"或"看 ahead",一次性比较接下来的 8 个元素,检查是否有任何元素足以进入 top-k。如果 8 个元素中没有任何一个需要插入,就可以直接跳过这 8 个元素,减少每元素的比较总量。实现中常用的技术是把当前最小的 top-k 值广播成 __m256i,然后用 _mm256_cmpgt_epi32 与 v_next(一次加载 8 个连续元素)比较,随后用 _mm256_movemask_ps 把比较结果压缩成一个整型掩码。掩码为零表示 8 个 lane 都不满足插入条件,可以跳过;掩码非零时就需要从这些候选中挑出要插入的值并逐个插入。
存在几种插入策略:简单策略是只插入掩码中最小的那一位对应元素,然后把数组索引移动到该元素的后面再继续,这样做可以减少重复比较但可能在某些分布上增加负担;另一种策略称为"剥离(peel)",在掩码不为空时把候选寄存器中所有满足条件的 lane 逐一提取并插入;最后一种则是如果掩码非零就不加判断地按 lane 顺序无条件尝试插入 8 次,依赖 insertNewMax_x4 对不需要插入的值是 NOP 的特性。不同策略在指令数量、分支行为和数据相关性方面的权衡不同。 用于提取单个 lane 的常见技巧是用 permutevar8x32 与一个广播的索引值来把目标 lane 置于低 128 位,然后从 256-bit 寄存器到 128-bit 的 cast 操作将其转换以便使用 SSE 的插入例程。示例伪代码如下: __m256i v_next = _mm256_loadu_si256((__m256i *)(v.data() + i)); __m256i v_cmplt = _mm256_cmpgt_epi32(v_next, v_minMax); int mask_lt = _mm256_movemask_ps(_mm256_castsi256_ps(v_cmplt)); if (mask_lt) { int lsb = ffs(mask_lt); // 1-based __m256i v_newCandidate = _mm256_permutevar8x32_epi32(v_next, _mm256_broadcastd_epi32(_mm_cvtsi32_si128(lsb-1))); insertNewMax_x8(v_maxSoFar, v_newCandidate); // 更新 minMax, v_minMax 等 } 性能基准与输入分布影响 在真实基准中,几类实现表现出截然不同的行为。对随机输入和逆序输入(即最小开销场景),AVX2 的 lookahead 变体整体性能显著优于标量实现与 STL nth_element。原因在于绝大多数输入元素在初始阶段就无法进入 top-k,从而使得每 8 个元素一次性的比较和快速跳过能够带来持续的吞吐率提升。
实验结果显示,AVX2 的批量检查变体比传统的逐元素实现快上几倍,吞吐量能达到数十亿元素每秒量级,而 nth_element 在这些场景中性能波动较大且总体较慢。 然而在已经排序的输入(最坏情形,即每一个新元素都比当前最小 top-k 大)上,奇妙的现象出现了:STL 的 nth_element 反而跑得更快,而 SIMD 变体反而表现不佳。可能的原因包括:在每次迭代都需要插入时,AVX2 那些看起来很少的向量指令可能比简单的栈上三元插入所需的标量指令复杂得多,而且 SIMD 指令往往会触发处理器的频率降级(尤其是宽向量指令集下),导致整体吞吐量下降。此外,频繁的数据依赖(每次插入后必须读取新的 minMax 并广播)削弱了指令级并行的潜力。也有可能是 nth_element 在已排序数组上恰好选择了良好的 pivot,从而在内循环采用非常高效的路径,结合缓存局部性与分支预测带来优势。 工程折衷与实践建议 SIMD 优化并非万能解。
对 k 很小且 top-k 很快确定的场景,尤其是当输入大且大多数元素很快被筛除时,寄存器内保持 top-k 并结合批量预检的 AVX2 实现能带来显著加速。关键优势在于:减少内存访问,避免对小数组的频繁循环移动,把插入操作变成一组固定的向量指令。然而在每个输入元素都频繁需要更新 top-k 的场景,寄存器内向量化的指令成本、频率下调、以及数据依赖可能抵消并行化带来的好处。 工程实践建议包括:先用简洁的标量实现或 STL 函数作为 baseline,再针对典型输入分布做基准测试。若工作负载确实显示出"多数元素无需更新 top-k"的模式,再投入 SIMD 优化,否则优先考虑代码可维护性与可移植性。对 SIMD 实现,推荐使用两阶段策略:在热路径上使用批量检查(每次加载 8 或更多元素并用 movemask 快速判断是否需要进入插入流程),若需要插入则调用高效的寄存器插入例程;另一个折衷是仅在输入足够大或动态检测到合适的输入分布时启用 SIMD 路径。
扩展:k>8、AVX512 与多寄存器策略 当 k 超过单寄存器能够容纳的元素数时,需要使用多个寄存器或迁移到 AVX512。AVX512 不仅扩大了每寄存器能容纳的元素数(16 个 32-bit),还带来更丰富的掩码寄存器与压缩/扩展指令,能显著简化插入逻辑。多寄存器策略需要在寄存器组之间执行比较与合并操作,或采用分段维护 top-k:先在各个寄存器组内维护局部 top-k,然后周期性地合并为全局 top-k。实现复杂度会上升,但在 k 在几十到几百之间且对性能有严格要求的场景中值得探索。 调试、移植和可读性考量 向量化代码往往难以读懂与维护,尤其是当大量异或、移位、混合以及置换指令交织时。建议把关键的寄存器操作封装成小而可测试的函数,并提供纯标量的回退实现。
保持代码可移植性可以采用条件编译或运行时的特征检测(如通过 CPUID 检查 AVX2/AVX512),并在构建系统中维护允许禁用 SIMD 的选项以便调试。对于性能敏感的项目,提供 micro-benchmark 用来回归测试不同输入分布下的表现是非常必要的。 结论与采纳要点 对第三大元素问题的 SIMD 优化揭示了现代处理器性能工程的一些常见课题:数据分布决定算法选择,寄存器内并行可以极大提升吞吐但也有频率与复杂度成本,批量预检是一个强有力的技术手段,而向量插入需要巧妙地利用比较、移位与混合指令来保持常数时间插入。实践中,如果典型输入显示大量无需更新 top-k 的元素,那么实现 AVX2 的 8 路批量检测并在需要时执行常数时间插入,往往能带来 5 到 7 倍的加速。但在极端负载下(例如输入有序且每个元素都需要更新),标量实现、STL 或基于小堆的实现反而可能更快。 未来工作可在几方面深化:用更精细的动态调度在运行时选择 scalar 或 SIMD 路径,探索 AVX512 下的掩码寄存器与压缩指令来减少数据搬运开销,以及对多寄存器方案的合并策略进行成本模型分析。
对于工程师而言,推荐先以清晰正确的基线为起点,在真实数据上进行基准,然后在确认收益时再用 SIMD 优化换取额外的复杂度。 。