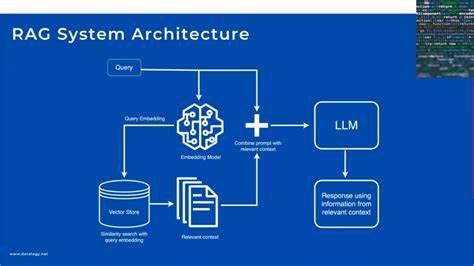
在人工智能技术快速发展的今天,检索增强生成(Retrieval-Augmented Generation,简称RAG)作为一种融合检索与生成能力的新兴技术,正成为企业实现智能化转型的重要工具。然而,对于众多企业而言,从理论模型到实际大规模生产部署,依然存在诸多挑战。如何在保证模型可靠性的前提下快速上线应用,避免 costly 的失败,并持续通过数据驱动实现价值最大化,成为企业关注的焦点。本文深入探讨企业如何系统地构建、评估及优化RAG系统,助力从实验室研究迈向业务落地,打造面向未来的智能系统架构。 检索增强生成技术结合了知识检索和生成式语言模型的优势,实现信息精准调用与自然语言生成的有机融合。通过先检索相关文档或知识片段,再利用这些信息辅助语言模型进行响应生成,RAG显著提高了模型答案的准确性与信息丰富性。
对于企业来说,这意味着可构建更智能、更可信的信息服务应用,如智能客服、知识管理、决策支持及自动化内容创作等,大幅提升业务效率与用户体验。 然而,理论模型往往只能证明方法的有效性,离实际应用尚有距离。企业面临的第一大挑战是如何构建生产就绪的RAG系统。需要从基础研发扩展到涵盖系统架构设计、数据流管理、模型版本管理、监控与容错等多个维度。合适的工程框架应支持海量文档索引、多租户场景以及高并发请求,保证系统的稳定与扩展性。采用模块化设计,分离检索与生成模块,确保灵活替换与升级,同时结合缓存机制与异步处理提升响应速度。
降低模型"幻觉"或错误生成,是RAG大规模部署的另一核心难点。生成式模型在生成答案时可能掺杂错误信息,严重影响用户信任。为此,必须建立严苛的评估体系,通过多维度指标(如准确率、召回率、生成答案与检索内容的一致性等)评估模型效果。结合人工审核与自动化检测,及时发现并修正潜在风险。此外,引入后处理机制,如答案可信度评分、多轮交互确认、基于规则的纠错等,有效减少错误和偏差,提高输出质量。 数据驱动的持续优化策略是实现最大投资回报率的关键。
企业应建立完整的数据采集与反馈流程,实时监控系统使用情况、用户行为与反馈,挖掘隐含需求和性能瓶颈。通过A/B测试、在线学习等实验方法,快速迭代改进模型与检索策略,提升系统效果。同时,利用指标体系进行多维度分析,指导数据标注、模型训练与架构调整,打造成熟闭环的智能运维体系,推动业务价值持续增长。 此外,企业规模化应用RAG还需关注合规性与安全性。处理敏感数据时应严格遵守隐私保护法规,采用数据去标识化、访问控制、审计日志等技术保障用户隐私与数据安全。在模型训练过程中,注意避免训练数据偏见,确保结果公平公正。
结合多层防护机制和应急响应预案,构筑稳健可信的AI系统。 未来,随着基础模型和检索技术的不断演进,RAG有望在更多复杂场景展现强大潜力,如跨语言跨领域知识整合、动态知识更新、个性化推荐与生成等。企业应紧跟技术前沿,积极探索创新应用,不断完善生态体系,推动企业智能化迈上新台阶。 总结来看,企业规模化部署RAG涉及技术研发、工程实现、风险管理和业务驱动等多方面协同。只有将理论方法与实践经验紧密结合,构建系统化的建设与运营框架,持续进行数据驱动的性能优化,才能真正实现RAG在企业中的落地与价值释放。未来,RAG有望成为企业提高智能服务质量、增强竞争优势的重要利器,助力数字经济时代的转型升级。
。