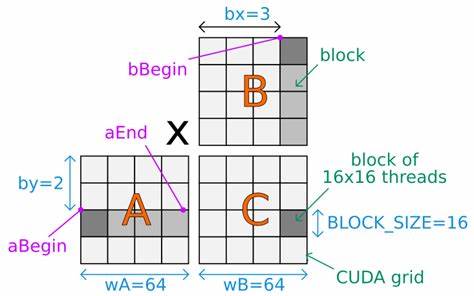
矩阵乘法是深度学习与数值计算中的核心算子,也是 GPU 优化研究的重点领域。虽然矩阵乘法的算术复杂度看似固定为 O(mnk),但在实际 GPU 实现中,性能往往受限于内存层次结构、带宽和并行化方式。平铺(tiling)是一种通过数据重用来提高内存效率和整体吞吐的关键技术。本文从数学与工程角度系统阐述平铺与朴素实现之间的差异,给出性能模型,并讨论在 CUDA 编程中如何选择与权衡平铺参数以获得最优性能。 首先从最简单的朴素算法说起。设 A 是 m×k 矩阵,B 是 k×n 矩阵,输出 O 为 m×n。
朴素的三重循环实现中,每个输出 O[i,j] 通过对 k 个乘加求和得到。若不考虑任何数据重用或缓存,计算过程中每次需要从全局内存加载对应的 A 元素与 B 元素。以元素访问次数计,朴素实现需要 2·m·n·k 次内存读取(每次乘法对需要两个输入),若采用半精度 FP16 表示,每次读取为 2 字节,从全局内存传输的字节数为 4·m·n·k。相应的浮点运算量为 2·m·n·k 次浮点运算,因此原始算法的算术强度(Arithmetic Intensity,FLOPs/byte)为 (2·m·n·k) / (4·m·n·k) = 0.5 FLOPs/byte,对于半精度数据这是极低的强度,意味着在大多数 GPU 上计算将被内存带宽严重限制,而无法充分利用高速的算力资源。 平铺的核心思想是把输出矩阵划分为若干大小为 b×b 的子块,使一个线程块负责计算一个输出子块。对每个子块而言,只要将对应的 A 的 b 行片段和 B 的 b 列片段载入共享内存,并重复利用这些数据来生成 b×b 个输出,就可以把每次加载的数据贡献到更多的乘加运算中。
更形式化地分析,假设输出子块大小为 b,那么每个子块在 k 维上仍需读取完整的 k 长度数据,但每次读取的是 b 条行或 b 条列,总的输入元素读取量为 2·b·k。输出矩阵中共有 (m/b)·(n/b) 个子块,因此总的内存读取次数降为 2·b·k·(m/b)·(n/b) = 2·m·n·k / b。与朴素算法相比,内存访问次数恰好被缩小了 b 倍,于是算术强度提升为原来的 b 倍,变为 0.5·b FLOPs/byte。由此可见,增大输出子块 b 能显著提升算术强度并缓解带宽瓶颈,最终可能把计算从内存带宽受限转为算力受限,从而更接近硬件峰值性能。 然而,平铺并非可以无限增大 b。限制来自于共享内存大小、寄存器资源和线程并发度等硬件约束。
对于每个子块,若将整段长度 k 的数据一次性全部保存在共享内存中,则需要存储 2·b·k 个元素,加上 b·b 个输出累加寄存器或共享内存位置。以半精度为例,总字节数约为 2·(2·b·k + b·b)。在 NVIDIA V100 等 GPU 上,共享内存大约为 64KB 或 96KB(依配置),当 k 很大时 2·b·k 项会主导空间消耗,因此 b 的最大值受限于 b ≤ S / (4·k·sizeof),其中 S 是可用共享内存大小,sizeof 为每元素字节数。举例说明:当 k=4096、S≈96KB、sizeof=2 字节时,可直接放入共享内存的 b 大小通常只有个位数或十位数,远不能达到理想的上千或上百的子块尺寸,从而限制了通过单纯增大 b 来提升算术强度的可行性。 为了绕过共享内存大小对 b 的限制,常用策略是对 k 维再做分块,记为 l。也就是说,在计算每个输出子块时,不再一次性读取所有 k 维的数据,而是把 k 分成若干段,每次加载 k 的一个子段长度 l,再对该段做部分乘加(partial accumulation),所有段累加起来得到最终输出。
此时每次加载的输入元素数目为 2·b·l,所需共享内存大小变为与 l 成正比,为 2·b·l + b·b。通过选择合适的 l,可以使共享内存占用满足硬件限制,代价是在 k/l 个阶段中对输出子块进行多次写回或多次累加。每个阶段会产生一次对输出寄存器的写或一次对共享输出的累加,写操作的增加会带来额外开销,不过这些写通常发生在高速共享存储或寄存器中,代价远低于从全局内存重新加载大量输入数据,因此总体仍然能显著提升性能。 用分块参数 l 的视角来重写总内存访问代价,可以得到:每个输出子块在 k 上需要 k/l 次阶段,每个阶段需要读取 2·b·l 个元素,因此总读取量仍为 2·b·k。把子块计数 (m/b)·(n/b) 乘上即得到 2·m·n·k / b,与不分段的理论一致。也就是说,分段并不能改变总的数据移动数量,但让内存占用降低,从而使得大 b 的理论优势在实际硬件上变得可实现。
分段带来的实际损失主要在于额外的累加次数与写操作,且过小的 l 会导致阶段数过多从而增加同步与写回开销,因此 l 的选择也需要平衡。 性能模型上可以用 roofline 模型来直观衡量平铺的效果。设 GPU 的峰值带宽为 B(字节/秒),峰值算力为 P(FLOPs/秒),半精度下朴素实现的算术强度约为 0.5 FLOPs/byte。若 0.5 < P/B,则算法为带宽受限。将 b 倍提升强度后,算术强度变为 0.5·b。只要 0.5·b 大到使得 0.5·b ≥ P/B,就能将瓶颈从带宽转向算力,也就是说当 b ≥ 2·P/B 时到达计算受限区域。
以具体数字说明,设 GPU 带宽 B 为 900 GB/s,半精度峰值 P 为 112 TFLOPs(即 1.12e14 FLOPs/s),则 P/B ≈ 124.4 FLOPs/byte。带入公式得到需要 b 大约为 249 来达到计算受限,这显然远超共享内存能容纳的 b。因此在现实大尺寸矩阵下通过单纯的 output tile 放大 b 很难把算法完全带到算力上限,但平铺仍能显著提高算术强度并减少带宽压力,从而提升实际性能。 在 CUDA 实现层面,平铺通常映射为每个线程块负责计算一个输出子块,线程块内线程协作将 A 与 B 的子块载入共享内存,随后循环乘加并使用寄存器保存局部累加结果。关键实现细节包括内存访问的共线化和对齐、避免共享内存银行冲突、合适的线程分配和循环展开、以及寄存器压力控制。为了进一步提升吞吐,现代 GPU 提供了张量核心(Tensor Cores),能以更高效的方式完成矩阵乘累加操作,尤其适用于半精度或混合精度计算。
使用张量核心往往需要把数据布局与子块尺寸调整为硬件友好的形状,例如 16×16 或 8×8 的分段,以及利用 WMMA 或 CUDA 的 mma 指令集进行矩阵乘累加。在这些场景中,平铺概念仍然保持核心地位,但实现细节会偏向配合底层张量运算片段。 另一个必须考虑的工程因素是线程块的驻留率和并发性。每个 SM 的并行线程块数量受制于共享内存与寄存器使用量。过大的共享内存占用会降低每个 SM 上能同时驻留的线程块数,从而导致硬件资源不能充分并行利用,尤其在存在其他内核或流并发时更为明显。因此在选取 b 和 l 时,既要顾及提高算术强度,也要保证足够的并发度以覆盖内存延迟与隐藏指令延迟。
常见的折衷是采用中等大小的 b(例如 16、32),再通过 k 方向的分块 l 调整共享内存占用,使得每个 SM 能容纳若干线程块,获得最佳吞吐。 为了解决内存访问与同步开销,工程实践中常采用双缓冲、异步拷贝和软件流水线。双缓冲允许在计算当前子块乘加时提前发起下一段 k 维数据的加载,从而更好地重叠通信与计算。CUDA 提供的 async copy 指令和 cp.async 能够把全局内存到共享内存的传输与计算解耦,进一步降低内存延迟对性能的影响。软件流水线则通过重排循环与预取将多个阶段并行化,从而得到更高的带宽利用率和更少的等待时间。 调优建议方面,首先建议通过性能分析工具如 Nsight Compute、nvprof 或第三方分析器评估内核的算术强度、带宽利用率与占用率。
观察 L1/L2 命中率、全局加载带宽和共享内存带宽,可帮助判断当前瓶颈是内存还是算力。其次根据矩阵尺寸与数据类型选择合适的子块尺寸 b 与分段 l,目标是尽可能提升算术强度同时保证较高的 SM 驻留率。对大矩阵可优先考虑 k 方向分段以适配共享内存,再用 moderate b 增强重用。若硬件支持张量核心且精度允许,应尝试使用 WMMA 或 cuBLAS 的批量接口以获得进一步性能提升。最后,注意内存访问模式的布局与对齐,避免 stride 读写带来的非共线化访问,并尽量减少共享内存银行冲突。 总结而言,平铺不仅仅是一个简单的实现技巧,而是改变了矩阵乘法在内存层次上的数据流动方式。
数学上,平铺通过在输出层面复用 A 与 B 的行列向量,将全局内存访问削减了一个与子块大小成比例的因子,从而提升算术强度并减轻带宽瓶颈。工程上,平铺需要在共享内存容量、寄存器使用、线程并发和写回开销之间做出权衡。通过 k 方向分块、双缓冲与异步预取等技术,可以在有限的共享内存下实现接近理论最优的重用。对于会被带宽限制的应用,合理平铺几乎总能带来明显的性能提升;而在追求极限性能时,结合张量核心与平台特定的指令集,才能让计算真正逼近硬件峰值。面对具体问题时,基于性能建模与分析的迭代式调优是达成最佳实现的可靠路径。 。