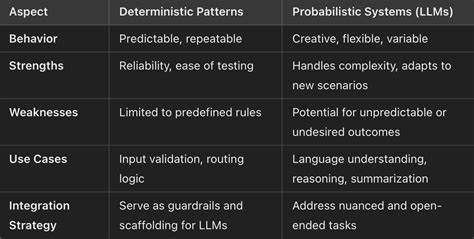
随着人工智能技术的迅猛发展,智能代理逐渐成为自动化任务执行和决策支持的重要工具。然而,围绕AI代理的核心设计理念,存在着一场日益明显的分歧:确定性代理与非确定性代理的对立。理解这两者的差异及其适用场景,对于推动AI在实际业务中的高效落地意义重大。确定性与非确定性,本质上是描述任务执行过程中输入、过程及输出是否保持一致的概念。在确定性框架下,给定相同输入,程序的执行路径和输出结果始终保持一致。这种模式类似传统的API调用,其稳定性和可预测性为企业级应用奠定了基础。
相比之下,非确定性代理则表现出高度的灵活性与多样性。它们基于语言模型和深度学习技术,能够根据输入和环境变化实时调整处理路径和结果,这在面向复杂或开放性任务时展现出独特优势。早期对AI代理的期望通常认为它们应当模仿人类处理任务的方式,具备自我推理和自主决策的能力,可跨多个任务和工作流灵活切换,完成多样化目标。然而,现实中的需求尤为复杂,特别是在面向企业级应用时,稳定性和可验证性成为首要考量。以医疗保险理赔流程为例,虽然整体目标是“理赔状态查询”,但具体实施细节差别巨大。美国市场上约有三千家医保付款方,其中只有四百五十家支持电子数据交换(EDI),其余主要通过邮寄、传真或门户网站等多样渠道反馈理赔状态。
每个付款方使用的拒付代码和说明互有差异,且类似代码在不同付款方处含义不一。理赔调整流程更是被大量“人治经验”和“试错机制”所主导,相同语义的任务在不同环境下往往须采取相应不同操作。人类理赔专员凭借丰富经验和灵活判断,能够高效处理这一多样化局面。然而,试图用单一非确定性代理通过一个庞大的提示词模型完成所有理赔相关任务,面对层出不穷的新门户、新数据格式、新规则,会导致执行路径极其复杂且难以保证一致性。浏览器类视觉语言模型(VLM)如Operator允许用户设定目标后让模型自主完成任务,但路径和结果的非确定性使其难以满足企业对稳定性和合规性的高要求。相比之下,将浏览器操作抽象为类似API的调用接口,辅以针对边缘案例的模型驱动自修复机制,能更好地平衡灵活性与确定性,将人类工作流转化为机器可访问的流程。
这种混合方法让模型能够在遇到异常时自动恢复,保证整体执行路径的确定性,避免严重异常给业务带来的风险。在企业级应用中,尤其是医疗、金融等领域,大量、高频、敏感的交易对准确性与低异常率提出严格要求。一旦系统输出变得非确定性且不可预判,即使异常率非常低,也可能造成数百起严重后果,影响合规审计和财务健康。因此,企业更倾向于选择具备确定性执行路径的AI代理,以获得高可靠性和可追溯性。写操作上的非确定性则几乎不可接受,因为在核心系统里任意一笔错误交易都可能引发巨大连锁反应。Substrate等企业级平台在满足这些需求时,采用了基于脚本的机器人流程自动化(RPA)、代码生成技术及视觉语言模型组合的混合解决方案,针对不同环境的静态或动态特征灵活调整,实现了稳定且高效的理赔状态查询及拒付申诉等任务。
这种方法既能维持高度标准化的核心工作流,又在边缘情况下表现出良好的适应能力。非确定性代理在某些场景下同样拥有不可替代的价值。例如,面向消费者的产品中,个性化和体验感更受重视,适度的路径和结果多样化能够带来新奇和惊喜,提升用户满意度。在这种环境下,异常往往被视为“特色”,反而增强了服务的吸引力。另一个典型场景是语音交互代理。与结构化界面不同,人与语音代理的对话极其开放且多变,使用者可能情绪波动、表达形式多样,维护一个完整的固定剧本成本极高。
非确定性的语音代理能够实时推理、灵活调整对话策略,更好地应对真实世界的复杂交流。语音代理中的人类相当于开放的“网站”,信息和行为几乎无穷无尽,需要代理具备极强的适应性和弹性。总结来看,AI代理的确定性与非确定性之间的矛盾根源于对稳定性与灵活性的不同需求权衡。在高度复杂且变化多端的任务中,非确定性代理展示出强大的能力,可以处理意料之外的情况与复杂语义理解。而在企业级大规模高频敏感操作环境里,确定性执行路径带来的可预测性、合规性及自动修复能力则是不可或缺的。未来,随着AI模型的不断进化和架构设计的优化,混合确定性与非确定性优势的方案将成为主流。
企业将在不同的应用场景下,根据任务的性质、风险及用户需求,灵活选择或整合不同类型的AI代理,以实现智能化、可控性与高效性的最佳平衡。正如医疗理赔系统所展示的那样,单一的非确定性策略难以满足规模化运作的需求,而纯粹的确定性又可能限制敏捷应变能力。只有将两者有机结合,辅以自动化和自修复机制,才能推动人工智能代理在复杂业务环境中的真正落地与广泛应用。面对这一分歧,技术开发者和企业用户都应深入理解不同策略的优劣,明确自身场景需求,打造符合预期的智能代理方案,为人工智能赋能社会经济注入全新活力。