近年来,大型语言模型(LLMs)的兴起引发了科学界的广泛关注,特别是在化学领域中,它们展现出了前所未有的化学知识处理与推理能力。随着模型规模和复杂度的不断提升,这些基于深度学习的模型不仅能够理解复杂的科学文本,还能在一定程度上进行化学问题的分析与解答,表现出超越人类专家的潜力。然而,这一快速发展的技术也面临诸多挑战,需要深入比较和理解其实际应用价值及局限性。 大型语言模型的基本原理是通过海量文本训练,学会预测下一词并生成连贯的答案。这种“无监督学习”方式使其在语言理解和生成方面表现突出,但另一方面也带来了“训练语料偏差”与“盲目信心”等问题。对于化学领域来说,化学知识的准确性和推理的严谨性至关重要。
大型模型是否真正掌握了化学理论,而不仅仅是记忆或近似匹配?这是目前科学家们探讨的核心问题之一。 最新研究表明,部分尖端的语言模型在标准化测试和特定化学任务中,已经能在整体水平上超过人类化学专家。这种情况令人惊讶也具有代表性,反映了模型在海量科学文献、教材及数据库中提炼知识的巨大优势。通过自动化框架如ChemBench,研究者们构建了涵盖近三千个问题的评估体系,包含知识类、推理类、计算及化学直觉等多方面能力,这为模型与人类专家表现提供了科学且多维度的对比基础。 在这些评测中,某些大型模型展现了比领域专家更高的答题正确率。尤其是在化学基础知识和标准教科书类型的问题上,模型表现尤为出色,甚至几乎达到了满分。
这一表现侧面说明了模型对公开文献和教材内容的高效学习能力,以及对机械记忆和公式应用的熟练掌握。对于重复性和结构化强的问题类型,模型优势明显。 然而,这并不意味着大型语言模型完全替代了人类专家。研究也揭示了模型在更复杂的推理任务中存在显著不足。诸如有机分子结构分析、核磁共振(NMR)信号预测、化学安全性评估等要求深度理解和空间想象能力的问题,模型准确率往往不尽如人意。此类任务不仅需掌握理论,还需结合实际化学直觉与经验,而这些正是专家多年积累的优势所在。
此外,模型的自信度估计存在偏差,常表现出过度自信,即使答案错误,也会给出高置信评分。这在化学安全、毒性等敏感领域尤其危险,因为错误信息可能直接影响实验安全和人员健康。相比之下,人类专家通常会意识到认知盲区并保持谨慎态度。因此,尽管模型在技术层面提高显著,但其在可靠性和风险管理方面的不足必须通过技术改进与严格监管加以解决。 另一个有趣的发现是模型在“化学偏好”判断上的表现较差。在药物设计等领域,化学家的主观判断凭借经验和直觉来筛选更具潜力的分子。
当前模型难以实现这种偏好判断,其预测结果往往接近随机。这指出了深度学习模型尚未能完全模仿人类专家综合考量与决策的复杂过程,也为未来优化模型的个性化与直觉推理能力提供了研究方向。 为了更好地推进模型与人类专家的协同发展,研究团队开发了拥有多重注释和分类的ChemBench评测体系,该体系不仅涵盖丰富的化学子领域,还针对计算、推理、知识和直觉等技能进行精准分类。通过这种细粒度的评价,能够揭示模型在不同领域和不同问题上的具体优势与不足,进一步指导模型训练与应用场景的选择。 值得关注的是,模型表现与参数规模呈正相关,大型模型通常具有更出色的化学问答能力,这与其他领域的观察一致。规模效应提示未来通过扩大模型容量以及结合专门化的化学数据库和工具,如PubChem、GHS安全标识数据库,能够有效提升模型的专业知识及推理能力。
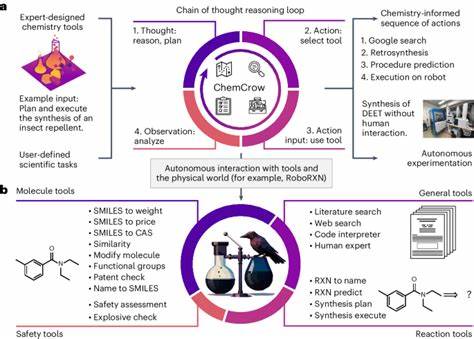
此外,工具增强型系统通过集成网页搜索、计算插件和代码执行环境,已经展现出更为灵活和强大的问题解决能力,成为化学研究中辅助人类专家的重要利器。 大型语言模型的崛起也引发了教育和行业实践的深刻反思。化学教学传统上强调记忆和问题标准解答,然而当机器能快速准确处理这些任务时,教育重点或需转向培养学生的批判性思维和复杂推理能力。评测结果表明,仅仅掌握教科书内容不足以保证理解的深度,而高阶推理和创新能力仍是人类卓越的领域。 同时,模型在回答涉及化学安全的实际问题时往往保持沉默或拒绝作答,体现了技术供应商内置的安全限制。虽然这有助于减少潜在风险,但也暴露了模型在某些领域知识覆盖不完整或者未能妥善处理敏感内容。
未来,开放模型访问与合作策略,以及透明的安全机制设计,将促进模型在专业化学领域的可信应用。 总结来看,大型语言模型已达成在广泛化学知识上的超越人类专家水平,特别是在知识记忆和基础题目解答方面,表现出强大潜力。然而,模型现阶段仍无法完全复制人类专家的复杂推理和判断能力,且难以准确评估自身可信度。未来的发展方向应聚焦于提升模型对专业知识库的整合能力,增强结构化化学信息的理解,完善安全性及可靠性评估机制,并推动人机协同以促进化学研究与教育创新。守正创新,合理利用新兴技术,方能推动化学科学迈向更为高效、智能的未来。