在现代软件开发过程中,调试是一项常见且关键的任务。程序员经常面对大量代码和复杂逻辑,导致诊断问题成为漫长且费力的过程。差异覆盖(Differential Coverage)技术作为一种高效的调试手段,能够帮助开发者更加精准地定位问题代码,从而大大缩短调试时间,提高开发效率。差异覆盖并非新鲜事物,类似于二分法查找的古老调试技巧,但在实际应用中远未被充分普及和重视。本文将深入探讨差异覆盖技术的原理、实践方法以及实际案例,协助读者掌握这一强大工具,优化调试流程。差异覆盖的核心思想非常直观:通过对比成功测试用例与失败测试用例的代码覆盖率,找出仅在失败测试中执行的代码块。
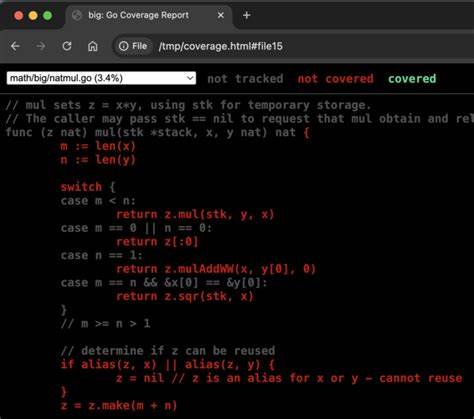
传统的代码覆盖率分析展示的是测试覆盖代码的整体情况,但在面对大量代码库和复杂测试场景时,单纯的覆盖率信息难以提供有效的调试线索。而差异覆盖利用通过对比差异所产生的独特覆盖区域,使开发者能够锁定与失败测试紧密相关的代码区域。首先需要收集两个覆盖率文件,即一个来自通过所有测试用例运行的覆盖测试,一个来自恰好失败的测试用例。这两个覆盖率文件会显示对应测试用例执行过程中覆盖的代码段。接着,将两者进行对比,筛选出只在失败测试中被执行的代码片段,这些代码片段往往正是潜藏缺陷的所在。以 Golang 的 math/big 包为例,开发者在一个边界测试用例失败时,利用差异覆盖技术快速定位到了导致错误的 natmul.go 文件。
失败测试的覆盖率仅覆盖了高达4.7%的代码,而通过的测试覆盖了85%的代码范围。通过计算差异覆盖率,发现只有少数的代码行在失败测试中独占覆盖,这些被标记为绿色的代码行最终被确认存在bug。除了定位问题代码所在,差异覆盖还提供了辅助分析能力。覆盖的绿色区块提示是潜在问题的重点区域,而红色区块表示失败测试中未触及的代码,可以被排除。未被执行的代码同样提供了启示,帮助排查测试输入和代码执行路径的偏差。例如出现某些函数未被调用,提示测试路径无法涵盖所有可能的逻辑分支。
事实上,差异覆盖的计算和展示过程成本低廉,但其正向价值巨大。面对数万行代码时,差异覆盖技术能大幅缩小诊断范围,让开发者在最短时间内定位核心代码问题,避免盲目翻阅大量无关代码。值得指出的是,差异覆盖并非万能。对于数据依赖性强的缺陷,有时通过覆盖率分析无法精确捕获。某些缺陷可能在多个测试中均被执行但未引发失败,因而不会出现在差异覆盖区域。此外,测试的敏感度和覆盖范围也决定差异覆盖的有效性。
因此,差异覆盖更适合作为辅助诊断工具,与其他调试方法结合使用。在实践中,使用差异覆盖也非常方便。以 Golang 为例,可以利用命令行工具快速生成覆盖率文件并通过标准比较工具提取差异,再配合官方的覆盖率浏览工具进行可视化分析。这种方式不仅提升调试效率,也便于团队共享问题定位成果,促进协作。差异覆盖技术不仅适用于失败测试,还能用于分析某些特定功能的执行路径。例如关注某一种网络协议的代码覆盖,可以通过选择相应的测试用例与基础测试对比,突出显示协议实现独有的代码路径,帮助功能验证和性能评估。
此外,差异覆盖也为测试覆盖率的评估提供了新的视角。传统覆盖率数据偏重全局覆盖,差异覆盖则能揭示单个测试或测试集执行的独特路径,帮助设计更全面的测试方案。随着软件系统日益复杂和庞大,自动化测试和代码覆盖工具的使用广泛普及,差异覆盖无疑成为调试工程师的必备技能之一。它有效整合了覆盖率分析和测试结果,创造出针对性强的信息,显著提升排错准确率和效率。总之,差异覆盖是一种简单却高效的调试技术。通过对比成功与失败测试用例的代码覆盖率,开发者能快速识别出潜在的缺陷代码,大幅缩短查错时间。
借助差异覆盖,面对大规模代码库时调试变得更加有的放矢,让程序员能专注于最关键的代码区块。未来,随着工具链的完善和智能分析的融合,差异覆盖的应用场景将会更加丰富,成为软件开发调试流程中不可或缺的一环。掌握差异覆盖技术,不仅提升个人调试能力,也助力整个团队的开发效率和软件质量保障。