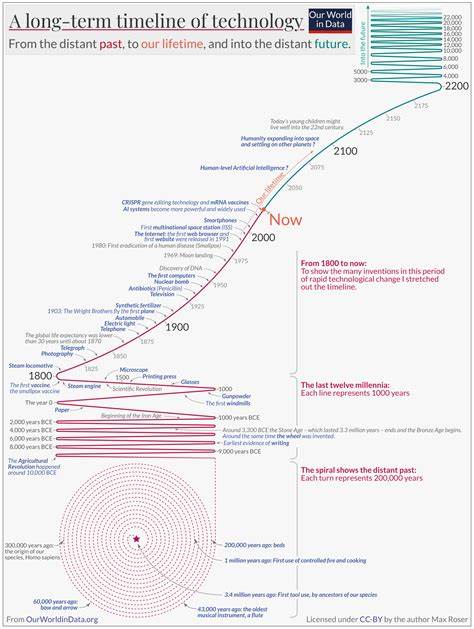
随着人工智能和机器学习算法的日益普及,越来越多的开发者渴望在实际项目中实现智能化解决方案。然而,AI模型的训练和部署不仅仅是算法本身的挑战,更需要强大的技术基础设施来支持。传统搭建这些基础设施既耗时又复杂,尤其是在面对如大规模语言模型训练这一高性能需求时,环境的搭建难度更是陡增。Kubeflow作为一个基于Kubernetes的开源机器学习平台,正是为了解决这一问题而诞生。它集成了70多个组件,能帮助开发者统一管理AI开发流程中的各个环节,包括数据准备、模型训练、模型部署以及持续集成和持续交付,极大地简化了AI开发和运维的复杂度。Kubeflow的名字就体现了其核心理念:利用Kubernetes构建流畅、高效的工作流系统,专注于机器学习和AI任务。
尽管如此,Kubeflow本身架构复杂,要想顺利部署运行,尤其是在本地环境或自建集群中,往往需要花费大量时间和精力配置各类依赖服务,例如etcd、Istio、DNS服务及容器镜像注册中心等。对于很多没有丰富Kubernetes运维经验的开发者来说,过程充满挑战,甚至会陷入困惑难以自拔。此时,选择云服务商提供的Kubernetes平台成为了更为高效和实用的方式。主要的云计算巨头如亚马逊AWS、微软Azure与谷歌云,都为Kubeflow提供了官方支持或高度兼容的部署方案,借助这些云上托管的Kubernetes服务,用户可以大幅降低部署难度并提升系统的稳定性和扩展能力。尤其是在AWS平台上,通过其弹性Kubernetes服务(EKS),我们能够快速搭建可用的Kubeflow环境,实现从用户管理到负载均衡甚至存储访问的完善集成。AWS提供的Cognito服务可方便地接管Kubeflow的用户身份和访问控制,极大地方便管理员进行权限管理。
Kubeflow默认集成的MinIO提供了与Amazon S3类似的存储接口,但在实际应用中,为了实现更好的性能与兼容性,很多部署倾向于进一步整合AWS原生存储服务,这也是Kubeflow灵活设计理念的体现——支持多种外部服务的接入,为不同需求和场景提供定制化方案。然而在AWS上运行Kubeflow并非全无代价。实际操作中,基础设施的创建及持续运行会产生相当可观的费用,尤其是当启用GPU实例进行深度学习模型训练时,成本可能快速攀升。为了避免预算失控,建议用户在AWS预算管理工具中设定花费上限和告警阈值,同时合理规划资源使用。此外,Kubeflow环境的搭建还需要域名支持。Kubeflow的监听和访问依赖于Amazon Route 53托管的域名或子域名,实现网络负载均衡和访问控制。
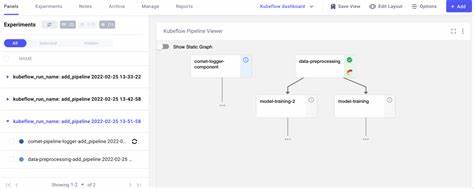
对于初学者来说,购置或委托管理一个专用的云域名会是更佳选择,既方便Kubeflow自动配置相关子域,又简化了集群外部访问的流程。值得一提的是,虽然Kubeflow采用开源模式,社区活跃且生态丰富,但由于其组件繁多且高度模块化,学习曲线陡峭成为不少入门者的绊脚石。对开发者而言,理解Kubeflow各个关键组件的功能及其相互关系,是掌握整个平台的关键所在。例如Kubeflow Pipelines作为核心,用于构建和管理从模型设计到训练再到部署的流程,提供强大的可视化界面和自动化调度。而Kubeflow Notebook Server则让用户能直接在集成的Jupyter环境下进行数据分析和模型开发,无缝对接TensorFlow、PyTorch等主流深度学习框架。此外,Kubeflow还支持模型服务化,例如通过TFServing组件,能够将训练好的模型包装为在线服务,方便API调用和集成。
随着人工智能需求的爆发,越来越多的高校、科研机构和企业将Kubeflow作为AI研发的基础平台。它不仅促进了从研究到生产的无缝转换,也推动了社区协作和创新。然而,成功落地Kubeflow需要结合具体业务场景,充分评估计算资源、团队能力与维护成本。对于刚入门的开发者,借助云厂商预配置的Kubeflow发行版,不失为开启AI项目的捷径。展望未来,随着AI技术的不断演进和Kubernetes生态的逐步成熟,Kubeflow势必在自动化、高效化和用户友好方面持续优化。通过提升图形化界面、简化安装流程以及增强对多云、多集群部署的支持,Kubeflow或将成为连接数据科学家与DevOps工程师的桥梁,实现真正意义上的端到端AI生命周期管理。
总的来说,Kubeflow不仅是一个庞大复杂的软件集合,更是人工智能开发者迈向工业级生产的重要利器。深入理解其架构优势与部署细节,结合云服务的弹性资源和管理能力,才能在现代AI浪潮中抢占先机。无论是学术研究还是企业应用,Kubeflow都为打造高效、可扩展的AI基础设施提供了坚实的基石,值得每一位追求智能化创新的开发者投入时间和精力探索。