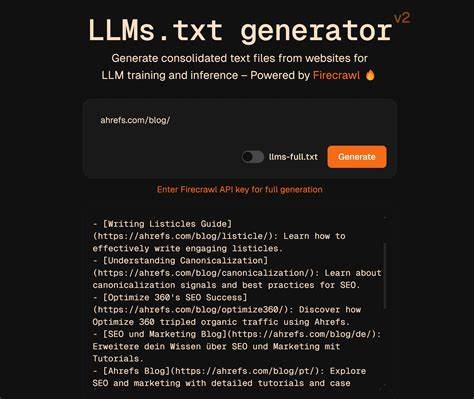
随着人工智能和自然语言处理技术的飞速进步,大型语言模型(LLM)如ChatGPT、Google Bard等逐渐成为信息获取和交互的重要工具。在这样的背景下,如何有效帮助这些模型识别和理解网站内容,成为业内热议的话题。llms.txt便是在此背景下提出的一种新型标准,旨在为大型语言模型提供结构化且高价值的内容导航指引。然而,尽管其理念听起来极具吸引力,目前llms.txt尚未被主流大型语言模型厂商正式接受和采纳,本文将深入探讨llms.txt的定义、实际应用现状以及其是否值得网站运营者和开发者关注。 llms.txt是什么? llms.txt是一个旨在为大型语言模型制定的标准文本文件,类似于我们熟悉的robots.txt和sitemap.xml。robots.txt用于告诉搜索引擎哪些页面可以抓取或禁止抓取,sitemap.xml则列出网站的页面结构,方便搜索引擎理解网站内容。
而llms.txt的设计初衷则是告诉大型语言模型,网站上的哪些内容是“重点”或“高价值”的信息,比如API文档、产品目录、退货政策等。通过提供这样一种结构化的导航文件,llms.txt试图消除大型语言模型在海量数据中“猜测”哪些内容重要的难题,让模型能够精准定位对用户回答最有帮助的原始资料。 llms.txt通常是采用Markdown格式编写,内容通过不同的章节分组,将网址路径组合成清晰、有序的目录。例如,可以将API文档、政策条款与产品信息分别归纳,从而清楚展示网页中的主要资源。 支持llms.txt的生态尚未建立 在理论上,为大型语言模型定制专属导航文件无疑是一种创新尝试,但实际应用层面并未取得广泛支持。根据行业调查,包括OpenAI、Google、Anthropic等主要LLM提供商并没有明确采用和解析llms.txt文件。
OpenAI的GPTBot虽然遵守robots.txt的指令,但对llms.txt并无官方支持。Google在其AI抓取行为管理中,依旧依赖用户代理和robots.txt标准。即使Anthropic发布了自己的llms.txt示范文档,但并无证据表明其AI模型真实读取和利用了这份文件。 这种局面反映了当前 llms.txt更像是一种尚处于规范构建阶段的“实验性”文件,而非已被广泛认可和应用的行业标准。创建和维护llms.txt文件对网站运营者来说相对简单,它无需复杂部署,只需将格式符合规范的Markdown文档放置于网站根目录即可。然而,由于缺乏主流模型的支持,llms.txt现阶段对提高网站内容被AI模型准确抓取和理解的帮助微乎其微。
值得关注还是暂时观望? 对许多从事内容营销和SEO工作的从业者而言,优化网站信息的展示及获取是核心追求。在这一背景下,llms.txt的概念无疑吸引了大家的目光,期待其能成为一种操控AI可见性的利器。但目前为止,还没有实质数据或案例表明llms.txt能显著提升网站的流量、索引排名或模型回答的准确度。 从行业专家的观点来看,llms.txt更像是一种“解决方案寻找问题”的状况。搜索引擎已经拥有完善的爬取和理解标准,LLM往往建立在同样的技术栈之上,他们能够直接分析网站内容,无需额外依赖类似llms.txt的文件。Google搜索权益倡导者John Mueller曾在公开场合表示,目前没有任何主流AI服务声明使用llms.txt,模型直接抓取并理解页面内容才是最有效的方式。
当然,技术发展的变数往往令人难以预测。虽然主流LLM厂商尚未采纳llms.txt,但如果未来该标准获得普及,作为早期采用者或许会积累先发优势。对已经拥有丰富结构化内容的网站来说,编写和部署llms.txt的成本不高,尝试构建文件不失为一种前瞻布局。但对于资源有限的小型站点或内容较为分散的网站,llms.txt目前并非必需。 未来发展趋势与思考 大型语言模型的发展正在不断推动生态体系的完善,围绕AI内容抓取、理解和反馈的规则也将逐步成熟。从长远看,类似llms.txt这样的标准能否成为普适工具,关键在于其是否能解决实际使用中的痛点,并获得主流厂商的支持。
当前阶段,站长和SEO从业者仍需关注现有搜索引擎和AI抓取标准,如robots.txt和sitemap.xml,这些已被广泛接受并切实影响内容可见性。与此同时,持续关注行业新动态和技术规范,保持适度试验和学习态度,有助于高效应对人工智能时代的内容传播挑战。 总体来看,llms.txt体现了业界在迎接AI内容抓取新形势下的探索精神。它尝试为大型语言模型设定一个结构化、明确的内容索引框架,意图提升信息检索效率和准确度。尽管目前尚无广泛应用和直接效果保障,但随着技术演进,其潜力不可忽视。对网站所有者而言,重点仍应放在打造优质、有结构化内容并合理管理网站抓取权限。
适时关注和试验llms.txt,有助于把握未来人工智能与内容生态的交汇机遇。