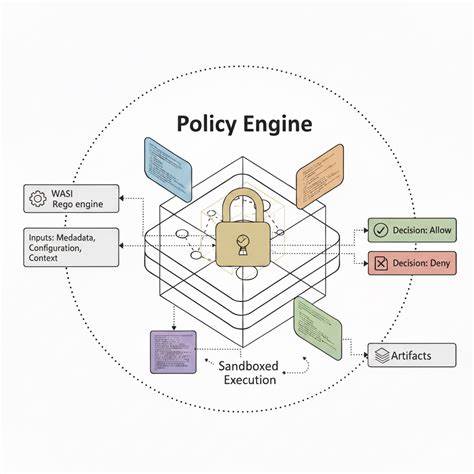
什么是 toil 以及为什么必须消除 在 Site Reliability Engineering 的语境中,toil 指的是那些重复、机械、与系统增长呈线性关系但不产生长期价值的运维活动。它通常以频繁的手动操作、重复的诊断步骤、噪声告警与简单但耗时的排查为表现。toil 的存在让团队长期处于被动响应状态,占用宝贵的工程时间和心理能量,导致创新受限、故障处理质量下降以及 on-call 倦怠加剧。消除 toil 并不是为了让人失业,而是为了把人力从低价值的重复劳动中解放出来,去做能够带来复利回报的系统改进和新功能开发。理解和度量 toil,才有可能做出优先级判断并采取有效措施。 如何识别和区分 toil 与真正的工程工作 要判断某项工作是否属于 toil,可以从几个维度观察。
首先看工作是否重复且可预测,如果每次出现都是几乎相同的触发条件和步骤,那么它更可能是 toil。其次考察这项工作是否需要工程判断或创造性思考,若工具人式操作居多则倾向于 toil。第三观察工作结果的持久性,如果一次完成并不会降低未来再次发生的概率,那么它没有复利价值,属于 toil。最后考虑工作负载是否随用户、请求或服务数量线性增长,如果是,就应优先考虑通过系统设计或自动化来消除。 识别 toil 的实操方法 让团队开展短周期的"toil 日志"是一个高性价比的起点。鼓励 on-call 和日常运维人员在为期五个工作日的窗口中记录每一次重复性操作,包括触发条件、实际步骤、耗时和对业务的影响程度。
通过汇总这些日志可以发现高频且耗时的痛点。用简单的打分法为每个事件赋分,依据频率、单次处理时长与对用户的影响进行加权排序。排序靠前的项就是优先消除的目标。将这些数据可视化,并在团队回顾中讨论,能够把隐性劳动显性化,形成共识。 衡量消除 toil 的关键指标 衡量的核心不在于复杂的仪表盘,而在于能直接反映团队"被动响应"负担的简单指标。首要指标是每周的 toil 小时数,采用滚动四周的平均值可以平滑偶发波动。
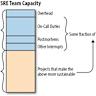
其次是 on-call 值班期间的告警次数和睡眠中断次数,这直接关系到团队健康。第三项是团队前五项重复性任务的持续追踪,包括每项任务的频率和处理时长。通过这三项指标,你可以评估执行消除措施前后的变化,设置明确的目标,例如在一个季度内将被动 toil 占比降至总工作时间的 15%-20% 以下。 消除 toil 的优先顺序与决策逻辑 在面对每一项识别出的 toil 时,应遵循一个优先顺序:避免优先于自动化,自动化优先于系统改造和外包。先考虑是否可以彻底删除这项工作,例如关闭无人使用的监控面板、合并冗余流程或调整告警策略,避免不必要的工作本身就是最省成本的消除方式。若无法避免,则评估是否可以通过脚本化或平台化将操作自动化,使之无需人工介入。
对于仍然需要人判断的流程,应探索如何通过系统改造降低发生频率或将决策推向更高层的自动化措施。最后可以将少量必需但低频的操作委派给更合适的团队或采用受限自助工具来降低对专家的依赖。 有效自动化的实践要点 自动化不仅是写脚本,更是将手工步骤转化为可重复、可审计、可回滚的流程。设计自动化时要从 idempotency 出发,确保重复执行不会带来副作用。添加重试机制、指数退避和熔断器可以让自动化在面对临时故障时表现更稳健。将自动化与事件上下文紧密关联,自动创建事件时间线并附带相关的指标、日志和部署信息,减少人为收集上下文的时间。
构建自助式平台与 chatops 工作流,可以让常见操作通过一键或命令调用完成,同时在后台记录审计日志以满足合规需求。自动化优先但要以安全为前提,每一项自动化操作都应包含有效的权限控制与回滚路径。 改进系统以从根本上减少 toil 有些 toil 来源于系统设计本身,例如频繁失败的批处理、长尾任务的人工重跑、易触发的告警等。解决此类问题需要回到设计层面,建立幂等的作业机制、使用死信队列和再处理UI、对失败场景进行合理重试并设置安全上限。优化默认配置和限额可以避免大量人为调优与紧急扩容。合理的缓存和预计算策略能够把原本需要人工核查的数据检索工作转化为系统输出。
衡量系统改进效果时,关注那些能显著降低操作频次或缩短单次处理时间的变更。 高质量的 runbook 实践 即便在高度自动化的环境中,仍然存在少数需要人工介入的稀有场景。为这些场景准备的 runbook 要遵循可执行性原则:步骤要原子可验证,避免大量复制粘贴命令。每一步都应包含预期结果和安全检查点,以及清晰的回滚步骤。将脚本化内容和 runbook 链接起来,让 runbook 更像是编排器而非命令库。鼓励在每次手工执行后更新 runbook,确保文档与实际操作保持一致。
良好的 runbook 不仅降低出错率,还能缩短新手接手的学习曲线。 告警与 SLO 驱动的优先策略 告警噪声是 toil 最常见的来源之一。将告警策略从资源指标驱动转向以用户影响为核心的 SLO 驱动方式,可以大幅减少不必要的中断。设定合理的错误预算,将那些不会立即影响用户体验的波动降为信息性事件,而把真正影响用户的退化作为必须的 paging 触发。利用多窗口的燃尽速率检测可以在告警触发时提供更稳定的信号。当告警不可避免时,自动绑定相关的时间序列、日志片段和最近的部署信息,减少人工上下文收集的时间成本。
文化与组织层面的变革 技术手段只能解决部分问题,真正的转变依赖于文化与激励的调整。首先让 toil 可见,公开分享被删除的任务,并像发布新特性一样庆祝"删除里程碑"。将团队目标与错误预算、on-call 体验和工程可交付物挂钩,促使产品与平台优先投资于可减少运维负担的改进。保护深度工作的时间,把可预测的运维窗口集中安排,避免打断式工作侵蚀工程师专注力。鼓励团队成员持续上报重复性任务并提出改进方案,形成从底层驱动优化的循环。 工具与平台的选择建议 选择工具时优先考虑集成性和可操作性。
一个能够将监控、日志、追踪、告警管理与自动化工作流联通的平台,能显著降低"寻找上下文"的时间成本。注重可扩展的自动化能力,如 webhook、可运行脚本的工作流与丰富的审计日志。对于中大型团队,构建内部平台或选择开放平台作为自助入口,可以把常见操作标准化并且施加必要的 guardrail。与此同时避免盲目堆栈过多点工具,工具过多反而会产生新的摩擦和管理成本。 实战案例:降低重复性告警带来的影响 一个典型的成功案例是将频繁的基础设施指标告警替换成用户级别的 SLO 告警。通过分析过去三个月的告警日志,可以识别出占比最高的几类噪声告警。
这些告警大多可以通过调整阈值、扩大时间窗口或将其降级为信息告警来减少干扰。与此同时,针对真正影响用户的渠道建立燃尽速率告警,结合自动化的初步诊断脚本和一键执行的修复命令,把人工介入的次数和处理时间同时压缩。结果是 on-call 团队的中断次数显著下降,工程师的可用于改进系统的时间增加,整体可用性也因此提升。 从零到一的实施路线图 要从长期角度推进消除 toil,可以按季度设定可衡量的目标。第一阶段是让 toil 可视化并做基线测量,收集团队一周的日志并生成优先级列表。第二阶段聚焦"避免"与"自动化",优先删除不必要的工作并把容易脚本化的流程交由平台完成。
第三阶段进行系统性改造,优化设计以抑制重复性问题的根源。第四阶段固化文化和工具链,把消除 toil 的实践纳入常态化的工程流程与绩效考核。每个阶段都应有明确的验证指标,用数据说话。 结语:把时间花在有复利的事情上 消除 toil 并不是一次性的工程项目,而是 SRE 工作方式的转换。目标不是变成一个没有工作的团队,而是把人从机械的重复劳动中解放出来,去构建更可靠、更高效、更有价值的系统。把"删除工作"作为与发布新功能同等重要的工程成果来对待,持续地衡量和优化,最终将团队的时间与注意力向长期价值倾斜。
通过识别、度量、优先处理和文化变革,任何团队都能把繁琐化为可控,把被动响应转为系统性的进步,从而实现真正的工程杠杆效应。 。