随着人工智能技术的飞速发展,大规模预训练模型在自然语言处理、图像识别等领域展现出巨大潜力。然而,训练规模不断扩大的模型对计算资源的需求也愈加严苛,传统集中式数据中心难以满足日益增长的算力需求。Node-0-7.5B项目的出现无疑为这一难题带来了解决思路与创新模式。Node-0-7.5B是一项基于互联网环境的多参与者、模型并行预训练合作计划,允许任何配备16GB以上GPU的个人或组织参与进来,共同协作训练一个超出单一设备能力上限的大型神经网络模型。该项目的独特之处在于其完全去中心化、无需许可的开放性,打破传统数据中心封闭环境的藩篱,让全球分布的计算节点通过互联网链接参与训练。项目历时三周,训练了超过360亿个token,汇聚了来自198个城市、44个国家的1642台GPU,总参与人数超过300人次。
如此庞大的分布式算力协同,实现了前所未有的训练规模和覆盖范围,充分展现了协同计算的强大力量。Node-0-7.5B采用了先进的模型并行训练方案,将模型分解并跨越多个计算节点并行处理。传统的模型并行多在高速数据中心网络下进行,因需要频繁传输激活值和梯度,通常要求极低延迟和高带宽。而Node-0-7.5B则开创性地实现了基于互联网环境的模型并行训练,通过创新的压缩算法极大降低了传输负担。项目团队引入了一种独特的权重约束压缩方法,将Transformer模型中的输出投影权重限制在一个共享学习的低维子空间中,借助Transformer层的递归结构,前向与反向传播中的激活和梯度压缩率超过99%。这种方法不仅大幅减少了传输数据量,同时保证了模型训练时的收敛稳定性,使得跨节点通信的时延和带宽限制得以突破。
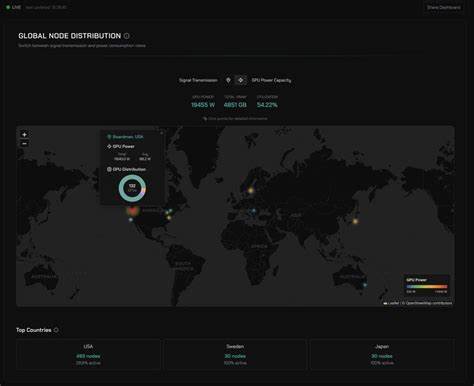
Node-0-7.5B的训练架构灵活且创新,支持多种GPU型号参与,如RTX 4090、3090、4060 Ti等,节点分布遍布六大洲,实现真正意义上的广域网合作。项目的动态分布式训练网络有效管理计算节点状态,即使部分节点因网络中断或资源变动退出,系统仍能保障训练的连续性和健壮性。该项目不仅验证了互联网速度相较于传统数据中心连接带来的可能瓶颈,也成功克服了分布式训练中节点频繁变动的挑战。结合压缩算法和协议模型设计,Node-0-7.5B展示了未来去中心化AI训练的可行路径。训练过程中,Node-0-7.5B使用了FineWeb-Edu数据集,共计1.3万亿tokens,采用了OLMo2-7.5B架构和每批次400万tokens的批量大小。如此规模的数据为模型提供了丰富的学习信号,确保了训练效果与质量。
此外,项目公开了丰富的实时仪表盘和节点分布信息,增强透明度和社区参与感。Node-0-7.5B的成功预示着AI研究的一个重要转折点 - - 未来大型语言模型训练不再依赖单一庞大机构或超级计算中心,反而借助全球算力共享与开放协同实现。一方面,它降低了高性能AI训练的入门门槛,推动算力民主化。另一方面,多参与者开放训练为模型多元化和创新提供了机会,降低了垄断风险。同时,项目中采用的模型压缩与通信协议创新,也为后续分布式深度学习技术提供了宝贵参考。Node-0-7.5B挑战了传统AI训练中对私有基础设施和高速网络依赖的固有思维,奠定了新一代分布式训练范式的基础。
未来,随着网络速度和计算硬件的持续进步,此类广域网协作训练方式将更为普遍,催生更多跨地域、跨机构的AI联合创新项目。此外,类似Node-0-7.5B的开源开放项目还能更好地汇聚全球人才和资源,促进AI公平、透明和可控发展。面对日益增长的人工智能应用需求和算力消耗挑战,Node-0-7.5B为行业提供了新的路径 - - 通过技术创新和社区共建,实现去中心化协作、资源高效利用和可持续发展的AI训练生态。随着更多参与者加入和技术不断完善,基于互联网的模型并行预训练将逐步走向成熟,推动人工智能走入更加多元和开放的新时代。总之,Node-0-7.5B不仅是一次规模空前的协作训练尝试,更是分布式AI技术的一次重大突破。它的成功既证明了多方协作的巨大潜能,也为未来模型训练的开放化、去中心化带来了现实可行的解决思路。
未来,拥抱类似Node-0-7.5B的协作模式或将成为推动人工智能进步的关键力量,激发更多创新活力,塑造更加包容和高效的全球AI产业生态。 。