随着人工智能技术的飞速发展,大型语言模型(LLM)在自然语言处理领域中展现出了前所未有的强大潜力。无论是文本生成、机器翻译,还是语义搜索和对话系统,LLM都成为了技术创新的核心驱动力。然而,传统的大型语言模型,尤其是基于Transformer架构的模型,在处理极长序列文本时遇到了严重的瓶颈。其核心机制——自注意力(Self-Attention)机制的计算和内存开销随序列长度呈二次增长,导致模型难以高效处理数十万甚至更多的上下文长度。为了解决这一困境,科研人员不断探索新的架构设计,力求打破二次复杂度的限制,实现真正的超长文本理解和生成。最近,一种创新的非注意力机制LLM架构成为业界关注的焦点。
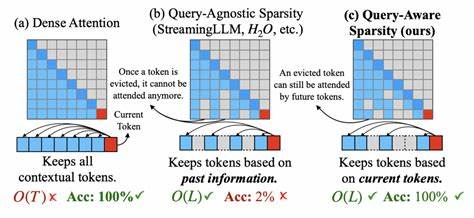
该模型放弃了传统Transformer中的自注意力机制,采用多种互补技术组合,在保持上下文理解深度的同时,将计算和内存需求降至接近线性,极大拓展了模型的上下文视野,实现对超长文本高效处理。这个突破性的模型架构集合了四大核心组件。首先是灵感来源于State Space Model(特别是S4模型)的状态空间模块,这一模块通过学习连续时间卷积核,能够高效捕捉长距离依赖,并且计算复杂度接近线性增长,极大提升了长序列建模的可扩展性。其次,模型引入了多分辨率卷积层,通过不同扩张倍率的卷积核并行处理局部上下文,细致捕获多层次、多尺度的信息,弥补单一卷积层的局限性。第三,设计了轻量级的循环监督机制,实质上维持了一个全局隐状态,在模型分段处理长序列时,能够保持整体上下文的一致性和连续性,有效连接了各个段落之间的语义桥梁。最后,利用检索增强的外部存储模块,模型在处理超长文本时将高阶的段落向量存储于独立的记忆单元,并在需要时进行高效检索,不引发任何二次复杂度的计算。
这种外部记忆机制不仅扩展了模型的上下文容量,同时保证查询过程高效稳定。 摒弃传统的自注意力机制,本模型避免了因序列长度增加带来的指数级计算和内存爆炸问题,使得处理几十万乃至百万级令牌长度的文本变得可能。实践中,这意味着模型能够一次性阅读和理解书籍级别甚至更大规模的文本内容,极大提升了上下文连贯性和推理能力。 这项技术不仅在理论上显示出优越的复杂度性能,还在实际应用中展现出了强大的竞争力。例如,超长上下文的处理能力对于法律文档、科研论文、编程代码库和历史档案等领域尤为关键。凭借此架构,模型能在无需分段剪辑的情况下,直接理解全文脉络,提升信息提取的准确度和生成结果的连贯性。
此外,模型的轻量化循环监督和多分辨率卷积模块为未来的硬件实现提供了良好的适配性,降低了部署门槛,使得高性能的超长文本处理成为更多组织和企业的可行方案。 随着对自然语言理解需求的日益增长,特别是在法律、医疗、金融等专业领域,能够处理极端长上下文的语言模型愈发重要。该非注意力机制的突破性设计预示着一种新的技术趋势:通过极致优化架构与算法,避开传统瓶颈,实现更大规模、更高效的智能文本处理。 从更广泛的视角来看,这一进展不仅推动了语言模型技术本身的创新,也为通用人工智能的实现奠定了重要基础。能够在超长文本中捕捉细微语义变化、理解复杂逻辑关系的模型,将更加接近人类认知的能力边界,为智能问答系统、多轮对话、知识图谱构建等应用带来质的飞跃。 未来的发展方向值得期待。
首先,结合这种非注意力机制架构与大规模预训练技术,有望进一步提升模型在各种自然语言任务中的表现和泛化能力。其次,围绕外部检索增强记忆的优化设计,可实现更加智能的上下文管理,支持跨文档、跨任务的知识融合与推理。最后,探索其与其他加速硬件的深度结合,将极大推动模型在实际应用中的速度和成本优势。 总体来看,突破传统Transformer的二次复杂度限制,采用非注意力机制设计的超长上下文大型语言模型代表了自然语言处理领域的重大突破。它不仅解决了当前深度学习模型在处理超长序列时的瓶颈难题,也为未来智能系统的发展提供了全新的思路和路径。随着相关技术的不断发展和成熟,这种非注意力机制架构势必将在各类语言理解和生成任务中广泛应用,成为推动人工智能迈向更高层次的重要力量。
。