近年来,随着大语言模型(LLM)的飞速发展,其在自然语言处理、生成式人工智能等领域的表现日益卓越。然而,如何在模型预训练完成后,通过高效的后训练手段进一步提升模型性能,成为业界和学术界亟需解决的难题。强化学习(RL)因其在策略优化、环境交互中的强大能力被广泛应用于LLM的后训练阶段,但传统强化学习框架因设计结构的限制,在面对大规模模型以及复杂任务流程时暴露出诸多瓶颈。AsyncFlow作为一款创新的异步流式强化学习框架,针对后训练过程中的多项痛点提出了有效的解决方案,极大提升了训练效率和资源利用率。首先,强化学习在大语言模型的后训练中发挥重要作用。通过与人类反馈、人类偏好结合,RL帮助模型更好地适应下游任务需求,实现更自然和准确的语言生成。
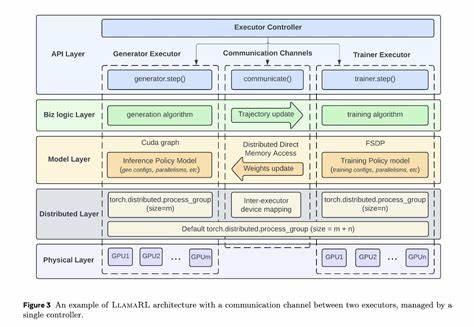
现有强化学习框架通常分为任务合并(task-colocated)和任务分离(task-separated)两类。任务合并结构在多个复杂任务同时执行时,由于资源调度紧密绑定,难以有效扩展,导致吞吐效率受限。任务分离结构虽然在任务解耦上表现出一定优势,但面临流程复杂化、数据传输效率低以及资源闲置等问题,影响整体训练效果。针对上述挑战,AsyncFlow提出了分布式数据存储与传输模块,以实现统一数据管理和细粒度调度。该模块支持全流式数据处理方式,通过网络高效传输数据,解决了传统框架中数据传递延迟和瓶颈问题。分布式设计不仅提升数据流通速率,还为异步任务调度打下基础,有助于自动实现阶段性任务的流水线重叠和动态负载均衡。
此外,AsyncFlow引入基于生产者-消费者模型的异步工作流,有效避免计算资源闲置。通过允许参数更新过程在符合陈旧度阈值的范围内延迟执行,该框架最大限度地压缩等待时间。训练过程中,系统动态调整各阶段任务的执行节奏,实现计算与通信的高效交叉,提升了整体训练吞吐量。值得一提的是,AsyncFlow的核心架构与底层训练及推理引擎解耦,转而通过面向服务的用户接口封装相关功能,极大降低了集成难度与使用门槛。此设计理念使得用户能够灵活定制训练流水线,支持多样化的训练引擎和推理工具,满足不同场景和需求的适配要求。这种模块化、服务化的架构也利于迭代升级,投射未来智能训练系统向着更开放、可扩展方向发展。
实验结果充分证明了AsyncFlow框架的显著优势。相比当前最先进的强化学习后训练框架,其平均吞吐量提升达到1.59倍,说明在保持训练质量的前提下显著优化了处理效率。这一提升不仅减少了计算资源浪费,同时降低了时间成本,对于大量模型迭代研发和实际部署具有重要意义。不仅如此,AsyncFlow的设计理念还为后续强化学习系统设计提供了宝贵思路。通过异步流式处理和细粒度调度,未来训练系统有望实现更高层次的自动化与智能资源管理,推动大规模模型训练进入新时代。总结来看,AsyncFlow在大语言模型后训练领域开辟了一条高效、灵活的创新路径。
它突破了传统强化学习框架的性能瓶颈,解决了复杂任务流程中的资源利用难题,通过异步流式设计实现了计算与通信的深度融合,带来了训练效率的显著提升。随着大规模人工智能模型训练需求的不断增长,AsyncFlow所代表的设计思路和技术体系,无疑将在未来增强学习领域及广泛的人工智能应用中,展现出更大的应用潜力与影响力。未来,结合更多智能调度技术、多模态数据处理能力以及更完善的用户定制界面,AsyncFlow框架或将引领后训练强化学习迈向更高效、更智能的创新阶段,推动人工智能技术实现更广泛更深层次的变革和进步。