随着大数据时代的飞速发展,企业在数据架构设计上面临着复杂的选择困境。数据湖以其灵活性和低成本受到青睐,但却难以保证数据一致性和查询性能;数据仓库则在稳定性和分析性能上占优势,却往往牺牲了存储成本的效率和数据灵活度。DuckLake作为DuckDB开源湖仓扩展,创新性地将数据湖的开源格式和数据仓库的ACID事务特性结合,实现了兼具灵活性和稳定性的下一代数据平台。本文将深入探讨DuckLake的架构设计、核心功能、应用场景及其如何为企业构建高效且可靠的数据湖提供强大支撑。首先,DuckLake的设计以Parquet文件为底层存储格式,Parquet作为开源列式数据格式,支持高效的压缩与编码方式,大幅降低存储成本。同时,DuckLake引入PostgreSQL作为元数据管理系统,确保所有数据操作满足数据库级别的ACID事务规范,从而保证了数据的一致性、隔离性和持久性。
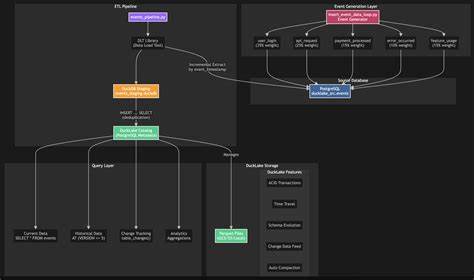
此外,DuckDB作为内置的分析引擎,以其卓越的单机分析性能支撑起实时和历史数据查询需求。通过Git类的版本管理机制,DuckLake为数据提供了时间旅行功能,允许用户方便地回溯任意时间点的数据状态,实现数据审计和变更追踪。DuckLake的体系架构主要包括三个关键组件:数据生成与采集、增量ETL处理以及数据湖中的最终落地和查询。数据生成环节通常是通过模拟或真实应用持续生成海量事件流,事件数据涵盖用户登录、API请求等多样化类型,保证数据的真实性和代表性。增量ETL阶段依托于DLT(Data Load Tool)工具,自动追踪增量数据,确保每次流水线运行只抽取新增或变更的记录,这不仅提高了处理效率,也保证了系统的容错性和运行稳定性。数据最终被导入DuckLake管理的路径,系统自动去重与合并,形成一致性的快照版本。
查询层面,DuckLake支持通过标准SQL语法直接访问湖中数据,不论是最新状态还是任意历史版本的数据均可自由查询。另外,DuckLake提供专门的函数用于查看版本差异,帮助数据分析人员及时洞察数据变化,便于故障定位和业务追踪。性能优化策略是DuckLake的一大亮点。系统自动执行小文件合并,降低了大量小文件带来的查询开销。同时基于列统计信息的剪裁机制加速数据扫描,仅访问符合过滤条件的分区和列,极大提升查询响应速度。数据分区功能进一步优化了存储结构,使得数据按日期等业务关键维度组织,更加易于管理和查询。
此外,鸭湖还利用DuckDB的智能缓存机制,减少了磁盘I/O,支持高并发的实时分析场景。在实际业务应用中,DuckLake已展现出了广泛的适用性。事件溯源场景下,它通过全量不可变事件存储和版本管理,使得企业能够无缝重放历史事件,快速还原系统状态。此外,作为变更数据捕获(CDC)平台,DuckLake可以详尽记录数据变更历史,确保数据审计的完整性与透明度。对于实时分析需求,DuckLake支持亚秒级查询,满足业务对最新数据的及时洞察,省去了复杂的ETL流程和OLAP系统搭建。数据科学家也能利用时间旅行功能在同一数据集上实验不同算法和参数,以确保试验结果的可重复性与稳定性。
面对复杂多变的生产环境,DuckLake内置了完善的监控和维护机制。定时调度ETL流程和数据快照过期任务保障数据持续新鲜与存储空间合理利用。定期执行文件合并和统计信息更新机制保证系统性能持续最优。成本优化方面,选用Parquet格式带来的10倍以上压缩效果,减少了存储费用。聪明的数据扫描策略减少了不必要的计算资源浪费。将数据存储和计算资源分布在同一区域使网络传输开销降至最低。
纵向通过智能缓存和列剪裁精细化资源利用,横向依托数据分区策略实现系统的平滑扩展。DuckLake作为数据湖与数据仓库融合创新的产物,完美地解决了两者之间的矛盾。它用开放的文件格式保障了数据生态的开放性与灵活性,借助健壮的元数据事务管理实现了企业级的数据一致性和安全性,杜绝了传统数据湖久拖不决的数据质量问题。同时,DuckDB内核带来的高性能查询能力让分析更加高效,支持各种复杂的实时和历史分析场景。通过简单的SQL接口和自动化的ETL与数据维护操作,降低了运维门槛,让更多企业能够快速搭建现代湖仓数据平台,摆脱对昂贵专有数据库系统的依赖。想要快速入门DuckLake,可以从官方GitHub仓库获取完整实例代码,按照示例搭建事件生成、增量ETL及数据湖查询流程。
结合环境变量配置和云存储路径即可完整运行端到端管道。社区活跃且文档详实,方便开发者快速掌握核心概念与操作技巧。综上所述,DuckLake以其独特的湖仓设计理念和丰富的功能特性,为数据工程和分析领域带来了具有变革意义的解决方案。面向未来,随着企业对实时分析和数据治理要求的不断提升,DuckLake无疑将成为实现现代数据平台转型升级的重要利器。持续关注DuckLake生态发展,积极参与社区交流,将助力企业数据资产价值最大化,推动智能决策和业务创新迈上新台阶。