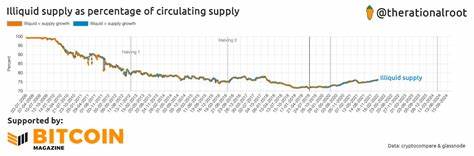
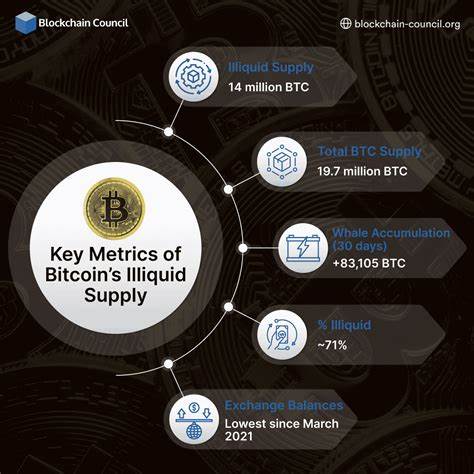
在人工智能飞速发展的时代,大型语言模型(Large Language Models,简称LLMs)逐渐成为科技界关注的焦点。它们以惊人的语言生成能力,改变了我们与信息交互与创作的方式。然而,真正理解LLMs的作用与局限,远非表面上看它们能够生成连贯文本那么简单。许多思考将其类比于柏拉图的洞穴寓言,认为这些模型不过是在墙上投射出的影子,虽然形象生动,但并不代表背后的真相。LLMs生成的内容缺乏真正的理解,仅仅是从已有数据中抽取语义并予以组合,这使得它们在某种程度上像是思维的起点,而非终点。尤其是在代码生成领域,这种影子性质变得更为明显:代码片段可以被立刻测试,通过实际运行检验其效果,从而分辨出"影子"是否映射到现实世界的有效操作上。
实践中,将LLM内置到知识管理工具如Obsidian中,可以自动整理凌乱的思绪碎片,生成一篇完整且语言优雅的博客稿件。虽然机器之作具备流畅的语言和轻松幽默的风格,甚至让人有欲立刻发布的冲动,但当回头细读时,却发现文本缺少了作者内心的"魂"。这种疏离感背后,反映的是作者身份与写作责任的深刻问题。回顾文艺理论,如《作者之死》以及"后人工写作"等当代研究,我们可以明白:作者身份并非简单体现在逐字逐句的输入上,而是在于对内容价值与意义做出取舍与判定的权利。LLM能够不断输出文字,但无法决定哪些段落应当公诸于世,哪些观点才真正代表作者自身的思考与态度。因此,人工智能的出现并非削弱了作者地位,反而凸显了一个不变的事实 - - 写作者是那些选择何种话语值得展示于世的人。
从技术深潜的角度看,当今软件开发环境正在经历巨大的变革。比如,针对复杂的TypeScript大型项目,传统编辑器可能因性能瓶颈而不堪重负。开发者尝试过多款编辑工具,比如Zed、VSCode甚至Neovim,发现在配置得当后,Neovim虽然轻量且高效,但熟悉的IntelliJ若解决性能问题,依然是最佳选项。"熟悉胜于新颖"成为实践的宝贵经验。在辅助辅助代码探索方面,新兴工具如Claude Code体现了AI在辅助编程上的潜力,但用户体验和适应周期仍需提升。身份认证和授权领域同样日益复杂。
从OAuth 1.0到OAuth 2.0,再到基于OpenID Connect的集成方案,开发者在不同系统以及遗留接口中穿梭,解决各种独特难题。OAuth 1.0虽显古老,却仍有其价值,在某些旧系统中难以替代。现代化的Ory Hydra堪称OAuth 2.0的利器,通过Kratos实现身份管理,Hydra负责授权流程,而Oathkeeper则充当访问代理,形成高效的身份访问闭环。然而,即使是这样完善的产品,在细节上也存在挑战,比如Kratos的邮件验证流程对用户体验的影响不容忽视。OpenID Connect的多方环境整合更要求开发者应对多样化的Claim映射、客户引用列表的复杂遍历,以及不同环境下的重定向URI白名单管理。构建一个灵活的映射器以协调多方客户数据,是实际开发中的重点难点。
近期在云原生开发中,一款名为mirrord的工具吸引了大量关注。它允许开发者在本地运行代码的同时,借助魔法般的手法,让代码仿佛直接运行在远程的Kubernetes集群Pod中。通过同步环境变量、文件系统访问,实现网络请求的定向劫持及路由控制,mirrord极大提升了远程调试的效率和安全性。特别是其HTTP过滤功能,可以精准拦截指定路径或包含特定头部的请求,避免对生产环境流量造成全面影响,保障线上系统的稳定。数据迁移及基础设施运维同样充满考验。以PostgreSQL数据库跨区域迁移为例,通过合理使用pg_dump和pg_restore命令行工具,配合诸如--no-owner、--clean、--if-exists等关键参数,可以避免数据恢复过程中的权限问题与冗余冲突,确保数据库切换的平滑过渡。
基础设施方面,针对OAuth授权服务器如Hydra所遇到的Ingress控制器限制问题,调整代理缓存区大小等参数成为绕过"login_challenge参数过大"限制的有效措施,显示了工程实践中的灵活应对能力。但Hydra生态中的系统密钥与客户端管理仍需细致打磨,以避免安全隐患。综合来看,LLMs代表了人工智能技术的一大进步,其在内容创作、技术开发辅助等领域发挥重要作用,但它们并非真正的"作者",而是产出内容的工具。作者身份归根结底依赖于人对输出内容的筛选与负责。与此同时,当代身份认证与云原生开发环境也在不断演进,推动着开发效率的提升和系统的稳定安全。技术创新与哲学思辨交织,共同揭示了数字时代人机关系的新篇章。
理解这些趋势与挑战,将有助于技术人员、创作者以及企业更好地拥抱变革,塑造面向未来的工作与创作生态。 。