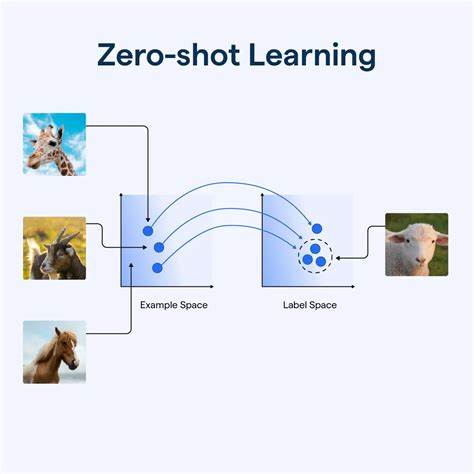
强化学习作为人工智能的重要分支,近几年得到了迅猛发展。通过与环境的不断交互学习,智能体能够自主探索并优化策略。然而,传统强化学习方法往往依赖于大量的训练数据和持续的环境反馈,这使得它们在面对全新或多变的现实世界任务时表现受限。零样本强化学习(Zero-Shot Reinforcement Learning)正是在这样背景下诞生的革命性技术,它致力于让智能体无需额外训练数据,即可直接应对新任务的挑战。零样本强化学习的核心目标是解决智能体在学习环境和实际部署环境之间的差异问题,突破传统强化学习普遍存在的环境偏差和训练数据匮乏的障碍。具体而言,智能体在训练阶段利用已有数据学得的策略,能够在未见过的任务或场景中迅速进行适应和决策,实现"零次尝试" 的高效迁移。
该领域的研究不仅融合了强化学习的理论基础,还涉及模拟环境构建、表示学习、多任务学习等多方面技术。构建精确且具有泛化能力的模拟环境是零样本强化学习发展的重要前提。现实世界中的数据通常十分有限且具有偏差,这造成模型训练时所依据的模拟环境与实际环境在动态、状态及奖励机制上的差异难以避免。此类差异被称为环境失配问题,一旦存在失配,智能体在真实环境中的表现往往不尽如人意。应对这种挑战,研究人员提出利用多源异构数据融合及自监督学习等方法,提升模拟环境的真实性及覆盖面,以增强智能体的泛化能力。零样本强化学习的另一个核心难题是部分可观测环境。
在现实应用中,智能体往往无法完整获取其所处环境的全部信息,状态信息不完整成为制约智能体表现的主要瓶颈。针对此,研究主张采用基于历史信息的记忆网络和概率推断机制,增强智能体的环境感知与判断能力,使其在不完全信息下依然能够做出合理决策。同时,通过设计鲁棒的策略更新算法,减轻环境变化对智能体学习策略的影响。此外,零样本强化学习还面临数据可用性有限的约束。许多高价值的应用场景中,获取足够的专家示范或环境交互数据极为昂贵甚至不可行。为降低对数据的依赖,创新性地引入了模仿学习、迁移学习等技术,帮助智能体在有限样本条件下提升任务适应力。
与此同时,强化对比学习、元学习等方法的结合,使模型能够从有限经验中快速提取有用知识,实现高效的零样本迁移。近年来,零样本强化学习在诸多领域展现了巨大的应用潜力。自动驾驶需要车辆在未见过的道路和交通环境中保证安全,而零样本强化学习可使自动驾驶系统无需大规模实地试验,快速适应新场景。机器人控制领域中,面对复杂的机械结构及多变的作业任务,零样本强化学习为机器人带来了更强的灵活性和泛化能力。医疗健康领域应用该技术,有望实现智能诊断和治疗方案的快速自我调整,提升个性化医疗水平。尽管进展显著,零样本强化学习的研究依然处在起步阶段,还存在待解难题。
例如,如何有效评估智能体在未知环境中的泛化能力尚无统一标准,实际部署中对安全与伦理的考量也亟需加强。此外,模拟环境的构建仍需平衡复杂度与精度,确保智能体训练时既不过分简化也避免误导。未来发展方向上,跨模态学习和强化学习的深度融合被视为重点突破口。通过结合图像、文本等多种感知信息,智能体将获得更加丰富的环境理解,提升决策的准确性。强化元学习的研究,旨在赋予智能体快速适应新任务的能力,进一步推动零样本强化学习向更广泛、复杂的场景迈进。整体来看,零样本强化学习为实现真正通用的智能体奠定了坚实基础。
借助不断进步的算法创新和计算资源,零样本强化学习有望在未来几年重塑人工智能技术格局,为自动化、智能化发展注入强大动力。随着行业对数据效率和适应性的要求日益增加,零样本强化学习无疑将成为激发新一轮智能革命的重要催化剂。 。