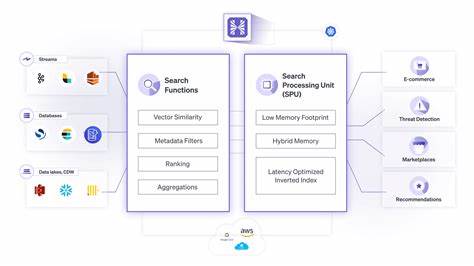
随着地理空间数据在城市规划、物流优化、灾害响应和机器学习中的应用日益增长,高质量、易用且高性能的矢量数据源变得愈加重要。Layercake项目通过将OpenStreetMap(OSM)原始数据转换为面向分析的Parquet格式,提供了一个能够直接在现代数据平台上高效处理的解决方案。通过合理的列式存储、空间预筛选和压缩策略,Layercake使得全球范围内的建筑、道路与定居点数据可以在几MB到几十GB的尺度上被按需读取,从而显著降低带宽成本并加快探索与分析速度。本文将系统介绍Layercake的关键特性、常见工具与实践方法,并分享在DuckDB、QGIS与通用ETL流水线中使用这些数据的实战建议与优化方向。Layercake提供的核心产物包括三个主数据集:Buildings(建筑)、Highways(道路)和Settlements(定居点)。这些数据以GeoParquet格式公开分发,并托管在高性能的CDN上,支持HTTP范围读取与按区域的边界框查询。
Buildings数据集体积接近40GB,包含数亿条建筑要素,属性字段丰富但高缺失率普遍存在。Highways数据集约25GB,收录全球道路要素,包含主干道到步道等多种highway标签。Settlements数据集相对轻量,主要用于城市与聚落定位与人口属性。这种按主题分层的组织方式便于面向任务的抽取,例如仅提取建筑几何与建筑高度相关字段用于城市体量分析,或仅提取道路网络拓扑用于路网可达性研究。Layercake之所以能在巨量数据下仍然高效,是依靠若干关键设计。首先采用Parquet这样的列式存储格式,使查询只需读取所关注的列而非完整要素。
对于建筑密集区,几何字段通常是占空间最大的列,而其他属性列往往占比较小,按需读取可以将带宽需求从GB级降到MB级。其次对数据进行了空间排序并在Parquet的row-group层面保留列的最小/最大范围统计,从而使支持范围读取的客户端(例如DuckDB或GeoParquet插件)能够在请求时通过HTTP范围请求跳过不相关的文件区域,仅下载对应的页或片段完成查询。第三,使用高效的压缩算法(例如ZStandard)对列数据进一步压缩,在保证可随机访问的同时减少存储与传输成本。在实际工作流中,DuckDB成为与Layercake数据交互的利器。DuckDB原生支持读取远程Parquet文件,并通过安装各种扩展(H3、spatial、json等)提供强大的分析能力。典型场景是通过READ_PARQUET函数对远程Parquet进行SQL查询,结合EXPLAIN ANALYZE可以看到HTTPFS统计信息、下载流量与查询时间。
由于Parquet的列/段级别统计,许多聚合查询仅需下载非常小量的数据。例如统计type字段的分布或按属性分组聚合时,DuckDB能利用列式访问与统计信息快速完成查询而无需拉取完整几何。对于本地交互,下载子集Parquet文件到磁盘再进行批分析,则能最大化读取与重复计算效率。QGIS与GeoParquet Downloader插件为桌面用户提供直观的可视化与边界框提取能力。通过在QGIS中设定视窗并使用GeoParquet Downloader的Custom URL选项,用户可以将远端大的Parquet文件按当前地图范围裁剪并下载,仅获得目标区域的数据子集。这在需要在地图上查看和手动检查要素时非常实用,避免下载整份几十GB的数据。
配合QGIS的2.5D符号化与表达式字段(例如将tags.height按规则转换为显示高度),可以直接在地图上渲染建筑体量,支持快速审查与可视化输出。同时,QGIS可以调用DuckDB脚本或本地SQL查询,对下载的Parquet进行统计分析或与其他矢量栅格图层联合分析。尽管Layercake提供了高效的数据载体,实际应用中仍需关注若干数据工程与质量问题。OSM数据本质为众包编辑,属性字段存在高度稀疏与多语种、多格式问题。许多属性以自由文本形式存储,导致唯一值数量巨大且包含噪声。例如building、roof:material、height等字段既含有规范标签也含大量非结构化输入。
为支持大规模统计与机器学习任务,通常需要对这些文本字段做聚类、规范化与词典映射。可采用字符串哈希、词频截断与小型编码表将高基数文本字段映射为有限的类别,再结合one-hot或嵌入表示用于下游建模。针对高度字段,常见做法是解析数值、统一单位(米为主),并对异常值与缺失进行插补或标记。自动化的ETL脚本可以利用DuckDB与Python生态在读取Parquet后进行批量清洗并将结果写回新的列式文件。在空间索引与切片策略上,可以结合H3等离散全局栅格索引将要素预聚合为多层级网格。Layercake当前的空间排序策略已能够显著减少范围查询成本,但进一步的优化可以在数据发布阶段导出额外的H3索引列或空间哈希列,便于快速按栅格统计建筑密度、路网长度或人口分布。
DuckDB的H3扩展允许在查询时动态生成H3索引并基于索引做聚合,从而实现高效的格网级别探索。对于需要全局或跨区域对比的分析,预计算的分区文件(按国家、行政区或H3单元)有助于并行化计算与缓存热点区域。从工程实践角度,带宽与延迟仍然是远程Parquet工作流中的重要考量。虽然HTTP范围请求可以大幅减少传输,但大量小的范围请求可能在高延迟网络下增加总时延。为缓解这一点,可以采用请求合并与预取策略,在客户端按row-group或按列段预估下载量并一次性拉取相邻片段,减少往返频次。DuckDB与一些HTTPFS实现已经支持合并范围请求的优化,但在高并发场景下,辅以本地缓存或CDN层缓存策略会更稳健。
另一个实用技巧是在初期阶段先运行基于统计的摘要查询(例如各字段的非空比例、独立值近似计数),借助Parquet的列统计来评估数据特征,从而决定是否需要下载更大的几何列以完成详细分析。安全与合规性在地理空间数据应用中同样重要。OSM数据大多属开源许可,但在整合到商业产品或用于敏感分析时,需要核对数据来源、贡献者许可证和隐私影响。Layercake的Parquet发布通常保留了OSM的原始标签,用户应在下游处理中对含有个人信息或潜在敏感标注(例如某些address或个体商铺标识)进行合规性评估与屏蔽措施。此外,在云端运行大规模空间查询时,应对访问控制与日志审计做相应配置,避免未经授权的数据暴露或滥用。Layercake项目的开放性也为社区贡献提供了机会。
项目的ETL脚本开源,鼓励开发者贡献更多针对OSM其他要素类型的解析与导出任务。潜在贡献方向包括但不限于交通设施(public_transport、bus_stops)、土地利用(landuse)、POI细分(amenity子类)以及建筑高度与三维信息的增强处理。为了让数据更适用于机器学习训练集,社区可以贡献规范化规则、公共词典和示例清洗流水线,这些将显著提升Parquet数据在产业界的可复用性。在应用案例方面,面向分析的OSM数据能在多个场景带来直接价值。城市规划师可以利用建筑与道路数据进行城市体量与空地率分析,评估新增开发对交通网络承载力的影响。物流企业可以在路网数据与建筑密度的基础上优化配送中心选址与最后一公里路径。
灾害响应机构能通过快速下载受灾区域的建筑与道路子集,进行受损评估与救援路线规划。研究人员可以结合定居点数据开展人口分布、城市化进程与夜间经济活动的宏观分析。机器学习工程师则可将Parquet格式的数据作为训练样本的空间参考特征,降低数据预处理门槛并加速模型迭代。要最大化Layercake数据的效益,推荐构建一套结合远程查询与本地缓存的混合工作流。在探索阶段优先使用DuckDB对远端Parquet进行快速采样与统计,利用列级统计与边界框裁剪筛选需要的区域与字段。确定分析方案后将核心子集下载到本地或云端对象存储,并在本地化数据上执行更复杂的空间分析、拓扑构建或批量转化。
对于重复性高的查询,建立基于H3或行政区的物化视图,以便快速响应业务查询并支持并行计算。通过这种分层存储与计算策略,可以在保持交互速度的同时控制存储成本和网络流量。展望未来,面向分析的OSM数据生态将继续演进。随着对三维建筑、室内空间与更多精细POI的需求提升,Parquet等列式格式与现代数据引擎将逐步支持更丰富的几何类型、有效的空间索引以及与时序数据的融合。开源社区在数据清洗、标准化和示例工作流方面的贡献将极大提升可用性。与此同时,云原生分析平台与边缘计算设备结合,将使得实时或近实时的地理空间分析成为可能,从而推动智能城市、自动驾驶与应急响应等领域的创新。
总结来看,Layercake通过将OpenStreetMap转换为Analysis-Ready的GeoParquet文件,为地理空间大数据的获取与分析提供了高效且可扩展的入口。结合DuckDB、QGIS与合理的ETL与缓存策略,用户能够在保证成本与效率的前提下进行大规模矢量分析。面对数据质量与文本自由度带来的挑战,采用自动化清洗、聚类与索引化措施可以显著提高数据在工程与研究中的实用性。持续的社区参与与工具链改进将推动这一生态系统成熟,帮助更多组织把开源街道与建筑数据转化为实际业务价值。若需在实际项目中应用Layercake数据,建议从小范围采样与统计开始,逐步搭建本地化的物化视图与标准化词典,以确保后续分析稳定、高效并可重复。 。