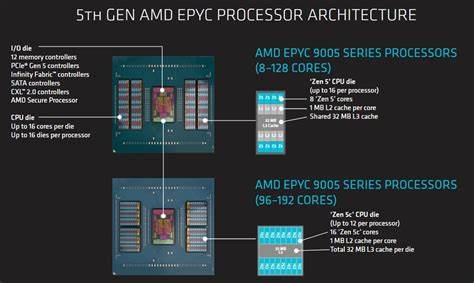
AMD 的 EPYC 9355P 以 32 核心身份进入服务器市场,但它并非简单地以较少核心换取更高频率那么直白。对于寻求单核性能、缓存密度与内存带宽平衡的部署场景,这款基于 Zen 5 架构的处理器展示了不同于以往高密度设计的策略。通过对其架构细节、I/O 互联、NUMA 特性以及基准测试表现的深度观察,可以更清晰判断在何种应用场景下选择 9355P 更具成本效益与性能优势。芯片布局与缓存策略EPYC 9355P 使用了八枚 CCD(核心计算模组),但每个 CCD 只启用四个核心,形成总计 32 个激活核心的拓扑。重要的是,每个 CCD 保持完整的 32 MB L3 缓存可用性,这带来了远高于核心数的缓存容量比,从而对缓存敏感型应用、延迟敏感服务与数据重复访问场景产生积极影响。较高的 L3 缓存容量意味着更多工作集能够驻留在缓存层,减少对 DRAM 的频繁访问,从而在带宽受限或高并发场景下提供更稳定的响应。
频率与能耗取舍在频率设定上,9355P 的单核 boost 可达到 4.4 GHz,明显高于很多面向极致核心数量的 Zen 5 服务器 SKU(例如 128 核或 192 核型号常见的 3.7 或 4.1 GHz)。更高的时钟频率有利于单线程和低线程数负载,但也带来更高的能耗密度与散热压力。AMD 在 9355P 设计中通过减少每 CCD 激活核心数量同时保持较高频率,试图在单核性能与总体功耗之间寻求平衡,从而为某些企业级工作负载提供更优的每核吞吐与延迟表现。IO Die 与 GMI-Wide的角色Zen 5 的服务器 IO die 提供了连接 CCD 与内存子系统、外部连通与 PCIe 通道的枢纽。EPYC 9355P 在 CCD 到 IO die 的互联上采用了 GMI-Wide 配置,为每个 CCD 分配两条 GMI 链路,使得 CCD 与系统其余部分之间的双向带宽显著增加。GMI-Wide 使单个 CCD 的读取带宽接近 100 GB/s,相较于桌面平台的单链路实现,能够更好地处理高带宽负载并控制在高负载下的延迟抖动。
该设计在面对读写混合、内存密集型工作负载时展现出更稳定的 QoS(服务质量)特性,减少了因单链路饱和而导致的延迟爆发。内存通道、带宽与实际测试样机装备一台 Dell PowerEdge R6715、768 GB DDR5-5200 内存以及 12 个内存控制器的配置,为 9355P 提供了接近 500 GB/s 的理论内存带宽。12 条内存控制器组合成 768 位的内存总线,使得芯片在高带宽场景中能够接近理论值,前提是应用在内存访问上进行良好并行化与节点亲和性管理。在实践中,单个 NPS4 节点对本地内存能达到约 117 GB/s 的带宽,而跨节点访问仅轻微下降到约 107 GB/s,说明内部互联延迟与带宽惩罚被很好地控制。NUMA 模式与延迟折中AMD 提供了多种 NUMA(非统一内存访问)配置:NPS1 将内存条带跨整个芯片,但代价是较高的本地访问延迟;NPS2 将芯片划分为两半,每半配置六个内存控制器,与 16 个核心构成一个 NUMA 节点;NPS4 则以四象限划分,每象限包含两个 CCD 与三个内存控制器。实测表明,NPS2 与 NPS4 对延迟只有边际性改善,且在某些高带宽场景下,NPS4 会因每个节点内可用内存控制器较少而降低单节点带宽能力,从而影响性能。
跨 NUMA 边界的惩罚相对较小,未加载情况下的最差跨节点延迟通常低于 140 ns,而在负载更重时也仅增加 20 到 30 ns。这意味着 9355P 的 IO die 与内部互联在拓扑优化上表现良好,能够快速调度跨节点请求,降低因节点划分带来的性能碎片化问题。GMI-Wide 在高带宽与加载延迟控制方面的优势尤为明显:在 GMI-Wide 下,单 CCD 在混合读写负载中既能实现高吞吐,也能避免桌面单链路在极端带宽竞争时出现的延迟飙升现象。负载特征对性能的影响与调优建议在 SPEC CPU2017 的若干测试中可以明显观察到不同处理器平台间的特性差异。单线程基准表现上,EPYC 9355P 相比同频率的高端桌面 CPU(例如 Ryzen 系列)仍有一定差距,主要源于更高的内存和互联延迟,以及服务器级功耗与散热策略对频率持续性的限制。然而,当工作负载转变为单 CCD 或少数 CCD 发起的高带宽浮点计算时,9355P 的大容量 L3 缓存与 GMI-Wide 带宽优势使其在某些浮点密集型测试中超过桌面平台与部分竞争对手。
尤其在面对像 549.fotonik3d 这类单线程但高内存带宽需求的任务时,桌面平台的本地内存延迟优势并未能转换为最终的吞吐率胜出,反而暴露出单链路带宽的瓶颈。系统管理员与性能工程师在部署 9355P 时应当考虑以下调优方向:在多数通用部署中,采用 NPS1 模式即可获得平衡的延迟与带宽表现,简化 NUMA 优化工作;对于对延迟极为敏感且线程亲和性明确的负载,可以尝试 NPS2 或 NPS4 并结合内存分配策略将数据就近放置;对于高带宽密集型负载,应避免将这些任务集中在单个小节点(如 NPS4 的象限)内,以免出现内存控制器瓶颈;利用 GMI-Wide 的读写混合优势,合理设计并发读写模式,可以降低单线程长时间占用单向链路导致的延迟激增问题。与竞争对手的对比与市场定位在与 Intel 最新 Xeon 平台的比较中,可以看到两种不同的设计哲学:Intel 倾向于更加逻辑上统一的互连与将内存控制器布置在更多的计算模组上以追求低局部延迟,而 AMD 则选择了以 IO die 为中心的 hub-and-spoke 设计,通过更均衡的内存访问与更大的缓存容量来换取更一致的跨芯片性能体验。在实际对比中,Xeon 在某些延迟敏感的短期访问场景可能占优,但 EPYC 9355P 在总体 DRAM 带宽、缓存利用率以及跨节点带宽一致性上具有明显优势,尤其适合那些无法线性扩展至超高核心数但要求单核与小规模并发高效利用的企业应用。结论与适用场景EPYC 9355P 并非对抗高核数阵营的简单替代品,而是为特定负载做出的有意识优化:通过降低每 CCD 的激活核心数并保留完整 L3 缓存、配合 GMI-Wide 提升 CCD 到 IO die 的带宽,AMD 为对缓存容量与单核响应有更高要求的服务提供了一个有吸引力的选项。典型适用场景包括需要较低延迟和较高单线程性能的企业服务、缓存敏感型数据库、内存带宽要求高但并非要求极大规模并发的数值模拟任务、以及一些需要稳定 QoS 的网络功能虚拟化场景。
对于寻求最大化核心密度的超大并行任务,传统的高核数 SKU 或者其他架构仍然更适配。同时,系统部署者应重视 NUMA 策略与内存分配的调优,尤其在采用 NPS4 或运行高带宽热点时,合理分配工作负载以避免节点级内存控制器饱和。总体来看,9365P 展现了 AMD 在 Zen 5 时代继续沿用并优化 hub-and-spoke 设计的成功:在保持良好跨节点一致性的同时,通过更高的缓存容量和更宽的 CCD 链路缓解了常见的带宽瓶颈。对于希望在服务器环境中兼顾单核体验与稳定带宽的用户,EPYC 9355P 值得在性能测试与预生产评估中优先考虑,配合恰当的 NUMA 和内存策略能够在实际负载中交付显著的性能与可预测性。 。