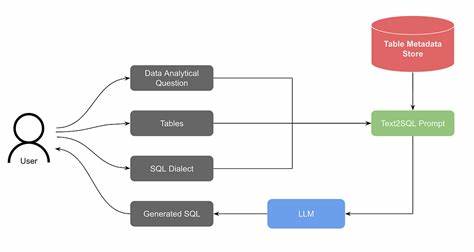
随着人工智能和自然语言处理技术的迅猛发展,如何让非专业用户也能轻松访问和操作数据库,成为技术领域备受关注的话题。传统的SQL查询虽然功能强大,但学习成本较高,限制了很多潜在用户的使用体验。为此,Text2SQL技术应运而生,通过将自然语言转化为结构化的SQL语句,极大降低了数据访问门槛。QueryWeaver作为开源领域的一款代表性Text2SQL工具,凭借其图语义层(schema graph)驱动的核心架构,正在引领新一轮的数据库交互变革。 QueryWeaver的技术核心在于将数据库的表结构、字段和关系等信息抽象成图数据结构,这种图语义层的设计能够更加细致和全面地理解数据库各元素之间的联系和依赖。在用户提出自然语言问题时,系统首先通过图模型深度解析查询意图,结合语义理解和模式匹配,生成符合业务逻辑和数据库规范的SQL语句。
这不仅提升了转化的准确率,还能有效处理复杂多表关联和模糊查询需求,极大增强了系统的适用性。 项目采用了Python后端搭配TypeScript前端的现代技术栈,提供了丰富的API接口支持,包括图结构管理、文本查询处理以及多种身份验证方式,满足不同应用场景下的系统集成需求。其支持通过REST API上传数据库模式图、查询已有图结构,并对话式地转化自然语言为SQL,这种交互模式使得非技术人员也能通过简单的提问,获得精准的数据库查询结果。 为了确保系统的灵活性和扩展性,QueryWeaver支持采用OpenAI和Azure OpenAI两种主流AI模型作为语义理解引擎。通过API密钥的配置,用户可以方便地切换和管理底层语言模型资源。此外,系统集成了Model Context Protocol(MCP)标准,通过HTTP接口开放服务,使得其他上下文敏感的应用可以无缝调用Text2SQL能力,实现多样化的场景融合。
从部署角度来看,QueryWeaver提供了基于Docker的快速启动方案,极大地简化了环境搭建流程。只需简单几条命令即可拉取并运行容器,无需繁琐的依赖安装,为测试和生产部署带来了极大便利。同时,项目附带详细的环境配置示例文件,帮助用户根据自身需求灵活调整参数,例如OpenAI密钥、OAuth认证配置等,满足从本地开发到云端部署的多种需求。 项目非常注重质量保证,集成了全方位的测试机制,包括单元测试和端到端测试。通过使用Playwright等现代测试框架,模拟真实用户操作和API调用流程,确保每次代码更新都不会影响系统稳定性。Github Actions持续集成脚本自动运行测试链路,并捕捉失败时的错误信息和截图,大幅提升了维护效率和代码质量。
QueryWeaver还具备社区友好性和开放精神,采用GNU Affero通用公共许可证(AGPL)发布,保障开源自由的同时促进合作创新。多位开发者和公司积极贡献代码和功能,使得项目不断演进,功能日益完善。此外,详细的开发文档和代码注释使得新手开发者能够快速上手,参与项目建设。 在实际应用中,借助QueryWeaver,企业和开发者可以显著降低数据分析和报告生成的技术门槛,无需复杂的SQL语法培训也能快速获取业务数据洞察。它适用于金融、电商、医疗、教育等多种行业场景,尤其适合需要频繁进行交互式查询和数据探索的场合。在数据驱动的时代背景下,利用自然语言赋能数据查询,无疑将提升工作效率并促进智能决策。
在未来的发展方向上,QueryWeaver计划进一步强化多语言支持和上下文理解能力,使得跨语言环境下的自然语言查询同样高效精准。同时,将探索和优化更深度的图神经网络技术,进一步提升语义解析和关联推理能力。此外,结合实时数据流和大数据平台的接入,将拓展其在实时分析和海量数据处理领域的应用空间。 总的来看,QueryWeaver代表了Text2SQL技术向更智能、更易用、更灵活方向发展的趋势。其通过图语义层的创新设计和开源社区的协同推动,为自然语言与数据库之间架起了一座高效桥梁,为数据获取赋能提供了强有力的技术支持。随着人工智能能力的不断提升,基于自然语言的数据库交互将逐步成为常态,QueryWeaver的诞生和发展无疑为这条道路奠定了坚实基础,值得关注和深入探索。
。