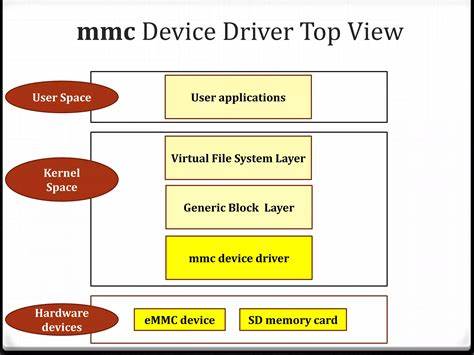
在现代信息技术高速发展的背景下,大规模日志数据的收集和分析已经成为企业数据运营的重要组成部分。无论是互联网企业、金融机构还是云计算平台,海量的日志信息为系统性能监控、故障排查、安全审计等提供了有力保障。然而,传统日志解析工具往往面临着处理速度缓慢、内存占用高、与分析工具不兼容等困境。针对这些挑战,Arrow-Powered Log Parser应运而生,它以Apache Arrow原生格式为核心,打造出一款高性能、内存高效的日志解析器,显著提升日志处理的效率和质量。 Arrow-Powered Log Parser是一款基于Go语言开发的日志解析工具,最大亮点在于直接将结构化日志转换为Apache Arrow的IPC格式。Apache Arrow是一种跨语言的内存内列式数据格式,支持零拷贝内存共享,适用于高效数据分析与传输。
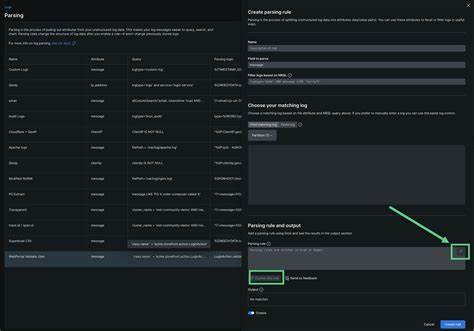
通过采用该格式,Arrow-Powered Log Parser实现了与主流数据分析平台如DuckDB、Polars和pandas的无缝集成,极大简化了后续的数据分析流程。 该解析器利用正则表达式的命名捕获组定义日志字段,实现灵活的、面向模式的日志结构映射。用户只需指定符合日志格式的正则表达式,即可自动推断字段模式并将文本日志流快速分批解析为Arrow数据批次。其内存管理设计高度优化,基于可配置的批量大小(默认每批10000行),保证处理大型日志文件时内存占用稳定且可控,避免了传统工具因内存暴增导致的性能瓶颈。 值得一提的是,Arrow-Powered Log Parser支持流处理模式,允许实时处理持续产生的日志数据,实现近乎恒定的内存使用,极大适合日志量庞大的生产环境。此外,解析时默认静默跳过无法匹配的日志行,用户可通过开启详细模式获取不匹配行的警告信息,便于日志质量监控和错误追踪。
针对正则表达式的合法性,该工具在启动阶段执行严格校验,确保用户输入的表达式有效且包含命名捕获组,保障解析流程的稳定可靠。 从性能角度看,内置基准测试显示Arrow-Powered Log Parser在中小规模日志文件的处理速度可达每秒50MB以上,大型文件甚至突破100MB每秒。相较于传统文本日志解析方案,其处理速度显著提升,内存分配次数和用量得到有效降低,极大增强了高并发处理场景下的吞吐能力。这种高效性不仅适合离线批处理,也支持流数据解析,满足实时监控和分析的需求。 在实际应用中,该工具赋能企业实现更快的数据洞察和更低的成本。通过生成兼容Apache Arrow的IPC文件,企业分析团队可直接利用DuckDB轻松完成SQL查询,或基于pandas和Polars进行复杂的数据清洗和机器学习准备工作,无需中间格式转换,流程简洁高效。
此外,零拷贝特性减少了数据加载延迟,提高了交互式分析的响应速度,极大提升用户体验。 开源属性是Arrow-Powered Log Parser的另一大优势。它完全采用Go语言实现,不依赖任何外部库或系统组件,易于部署和跨平台使用。开发者和运维团队可以根据具体需求灵活定制解析模式,扩展功能,或集成至现有日志处理流水线。同时,活跃的社区和持续的性能优化保证了工具的不断完善和可靠性提升。 展望未来,Arrow-Powered Log Parser计划引入自动类型推断、支持多种输出格式如JSON、CSV和Parquet、增强对多行日志的支持以及内置压缩功能。
这些特性将使日志解析更加智能化和多元化,满足不断变化的业务需求和大数据技术生态的新趋势。 总结而言,Arrow-Powered Log Parser通过融合Apache Arrow的高效存储格式与灵活多样的正则解析,开创了一条时间效率和内存效率兼备的日志处理路径。它不仅为大规模日志数据提供了一种极具竞争力的解析方案,也推动了数据分析与日志管理领域向实时、高性能和低成本的方向快速迈进。对于需要高速、稳定、兼容性良好的日志解析工具的企业和开发者而言,Arrow-Powered Log Parser无疑是一款值得关注和尝试的创新产品。未来随着更多功能的逐步完善,预计将成为日志数据处理中的重要利器,在大数据时代释放更大的数据价值。