随着云计算和物联网的发展,时序数据的规模与复杂度呈爆炸式增长。作为开源、水平可扩展的多租户时序数据库,Grafana Mimir一直在业界获得广泛关注,其核心优势在于支持大规模数据存储与查询分析。然而,传统采用Prometheus PromQL查询引擎在处理复杂查询时经常遭遇内存使用峰值过高的问题,限制了系统的整体稳定性和性能。为解决这一瓶颈,Grafana团队在Mimir 2.17版本中推出了全新的Mimir查询引擎(MQE),该引擎以流式查询方式重新定义了内存使用效率,开创了更快、更省内存的查询时代。 传统PromQL引擎在执行查询时,由于需要一次性加载所有匹配的时序数据样本到内存,导致内存峰值随被选中的时间序列数量和时间范围阶梯式增长。以"sum by(namespace) (http_requests_total{method=\"GET\"})"查询为例,传统引擎先检索满足条件的所有时间序列样本,然后在内存中进行聚合计算。
如此一来,若查询范围大或系列数量多,内存瞬间被撑爆,产生不稳定的内存利用率和频繁的资源调度压力,甚至引起容器故障重启,对整体监控系统的可用性和响应性能带来影响。 Grafana团队在大规模集群运营中,深入分析了内存消耗的根因,结合已有的优化手段如时间拆分及查询切片,尽管一定程度上缓解了问题,但仍无法从根本上杜绝内存峰值的波动。面对这一挑战,团队决定重新设计查询执行模型,摒弃传统一次性加载所有结果的思想,转而采用流式处理方案 - - Mimir查询引擎便是在此背景下诞生。 MQE的核心创新是实现"按需加载",避免将所有输入系列和样本同时放入内存。对于复杂聚合计算,MQE以流水线方式逐条处理匹配的时间序列,边读取样本边进行聚合运算,显著缩减了内存占用峰值。例如在之前提到的示例查询中,MQE不会一次性加载所有满足条件的上万条时间序列,而是单条加载、实时聚合,确保内存中同时只保留极少量输入及对应的结果样本。
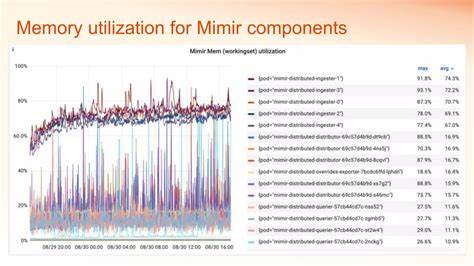
这种差异不仅减少了不可控的内存波动,更提升了查询的稳定性和效率。 实际应用场景中,采用MQE后,Grafana Mimir的查询前端和查询器组件均实现了内存消耗的显著下降,查询延迟也得到了同步缩短。在某些极端性能测试中,面对10万条输入时间序列以及多组聚合标签时,MQE的峰值内存使用仅为传统引擎的十分之一不到,查询速度提升近40%。如此大幅提升,不仅降低了云环境中资源成本,还提升了用户体验,确保多租户环境下不同用户查询的公平性和响应速度。 为了保障MQE的查询准确性,Grafana团队采用了双引擎并行验证策略。通过query-tee组件将同一查询请求同时派发给PromQL引擎和MQE,实时比对两者结果,确保新引擎在正确率和一致性上完全符合预期标准。
配合丰富的单元测试和PromQL脚本测试框架,这套严谨的验证体系保障了发布版本的高稳定性和可靠性。同时,MQE对所有稳定版PromQL特性保持百分百兼容,确保用户现有仪表盘、警报和查询不需任何修改即可继续使用。 此外,MQE通过在查询前端实现公共子表达式消除,避免重复计算相同操作,进一步加快查询响应速度和减少资源消耗。这一功能结合查询切片技术,将实现更加细粒度的性能优化,支持未来更大规模的时序数据生态体系。 Grafana Mimir MQE的问世,不仅是技术上的一次突破,更代表了时序数据库领域向流式计算架构转型的趋势。它解决了传统批量加载带来的内存瓶颈问题,为高并发、多租户环境下的复杂指标查询提供了坚实保障。
伴随着即将到来的Mimir 3.0版本,MQE将作为核心支撑,助力企业级客户构建更高效、更可靠的监控和观测系统。 总的来说,Grafana Mimir通过引入MQE,实现了查询性能和内存效率的双重提升。自2.17版本起,MQE已成为默认查询引擎,用户可通过简单配置自由切换,确保兼容性与平滑过渡。利用MQE,监控运维团队能够支持更大规模的指标数据,提升查询响应速度,同时大幅减少云端内存成本。展望未来,MQE将持续优化和扩展更多场景支持,不断推动Grafana生态系统的繁荣与创新。 作为开源项目,Grafana Mimir与其查询引擎背后的技术创新开辟了时序数据库发展的新方向。
对于关注性能与成本并重的组织而言,选择搭载MQE的Grafana Mimir,意味着迈入了高效、灵活且经济的监控新时代。无论是开发者、SRE还是企业决策者,都能从中受益,彰显数据驱动的力量。前往Grafana官方文档和社区深入了解MQE相关技术细节,为你的监控平台注入强大动力。 。