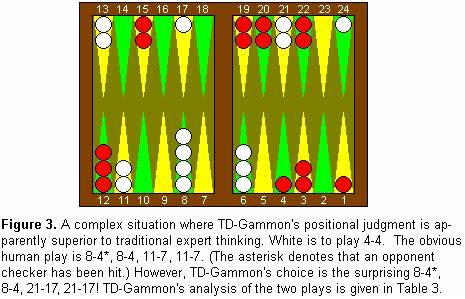
在人工智能领域,TD-Gammon被誉为早期强化学习应用的里程碑之一。作为一个专注于双陆棋(Backgammon)的计算机程序,TD-Gammon在1990年代由美国IBM托马斯·J·沃森研究中心的杰拉德·特绍罗(Gerald Tesauro)开发,以其独特的时间差分学习方法彻底改变了人工智能对游戏策略的理解。TD-Gammon不仅在竞技表现上接近顶尖人类选手,更在策略探索上展现出超越传统人类思维的能力,从而推动了整个背棋理论的发展。TD-Gammon的名称来源于其采用的核心技术 - - 时间差分学习(Temporal-Difference Learning),特别是TD-lambda算法。这种学习方法使计算机程序能够通过自我博弈不断修正自身对局面价值的评估,无需依赖人类专家的标注数据,体现了强化学习的精髓。通过多达数百万场自我对弈,TD-Gammon逐步优化其神经网络权重,实现了对不同棋局状态胜负概率的精准评估,并最终能够做出接近最优的决策。
TD-Gammon的核心组件是一种三层神经网络,输入层设计细致且兼顾了原始棋盘信息和专家设计的特征编码。这些特征涵盖了高级锚点(block anchor)、路障强度(home board strength)及被击中风险等关键概念,帮助模型更好理解复杂棋面。隐藏层负责整合和抽象信息,而输出层则通过四个神经元输出当前局面导致不同赢法(白方普通胜、黑方普通胜、白方双倍胜、黑方双倍胜)的概率估计。在实际决策过程中,TD-Gammon会搜索所有合法走法的后续局势,评估每个可能的结果,并选择期望胜率最高的走法。这种基于评估函数的搜索策略使得程序既能准确判断当前优势,又能预判未来对手的应对,从而提高整体实力。值得注意的是,尽管TD-Gammon在战术层面表现出色,但其局限性也十分明显。
程序采用的搜索深度较浅,通常为两到三层走法预测,这使得它在复杂且需长远计算的残局阶段效果逊色。同时,因训练过程中未充分考虑背棋中的倍数决策,TD-Gammon在加倍策略上也时有失误,反映了神经网络评估与传统理论的结合尚需改进。TD-Gammon的训练历经多个版本迭代,从最早的0.0版开始,逐步增加隐藏层节点数、自我博弈场数及搜索深度。1993年的2.1版本已通过150万场自我训练达到接近顶级人类选手的水平,甚至在1998年的一百局对战中仅以微弱差距输给世界冠军。这一过程不仅验证了其算法的有效性,也为强化学习算法的成熟奠定了坚实基础。除了竞技实力,TD-Gammon更对背棋界带来了深刻影响。
其通过自我博弈发现的许多非传统开局策略,打破了人类长期遵循的经验法则。例如,传统背棋中"slotting"(冒险摆放单个棋子以争取攻势)被TD-Gammon证实不如"splitting"(拆分棋子位置)稳健,导致许多职业选手调整自己的比赛策略。著名专家Kit Woolsey更指出,TD-Gammon对风险与安全权衡的精妙判断甚至超越了人类。这一切证明了强化学习不仅能模仿人类,甚至能够引领创新。TD-Gammon的成功激励了后来一系列强化学习和深度学习程序的诞生,例如深度Q学习和AlphaGo,它们进一步将人工智能拓展到更为复杂和多变的游戏环境。在学术领域,TD-Gammon也被广泛引用作为强化学习算法效果的经典案例,不断推动理论与实践的对接。
虽然TD-Gammon并未直接商业化,但它的影响力却体现在多个商业背棋软件的设计思路中,如JellyFish和Snowie等,这些程序直接借鉴了TD-Gammon的架构和训练理念,极大提升了人机对战的水平。总结来看,TD-Gammon不仅是一款高水平的背棋程序,更是人工智能研究的重要里程碑之一。它展示了通过自我博弈进行强化学习的巨大潜力,成功突破了传统人类专家经验的束缚,实现了从无到有的策略创新。TD-Gammon的故事启示我们,未来人工智能与人类智慧的融合将在更多领域创造出意想不到的成果,推动科技与文化焕发新活力。随着算法和计算能力的持续进步,期待类似TD-Gammon这样的机制将在更多比赛和决策环境中发挥关键作用,促进人工智能向更高层次的智能迈进。 。