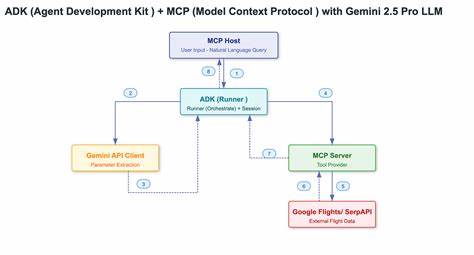
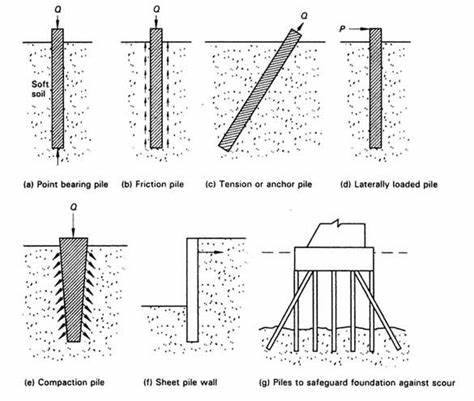
人工智能尤其是大型语言模型在推动自然语言处理和机器学习领域进步方面发挥了重要作用。近年来,随着前沿语言模型的不断涌现,大型推理模型(LRMs)凭借其能够生成详细思考过程的能力,在解决复杂推理问题时展现出显著的性能提升。然而,尽管这些模型在各种推理基准测试中表现优秀,其内在能力、扩展性及潜在局限依然未被充分理解。任何一项技术的全面评估都需要超越最终答案的准确率,深入考量模型推理路径的结构与质量,这也是科研人员当前关注的重点。传统评测方式往往聚焦于既有的数学和编程基准,这些测试存在数据污染的问题,难以准确反映模型真实的推理能力。为此,研究团队设计出可控的谜题环境,通过精确调控组合复杂度且保持逻辑结构的一致性,实现了对模型推理过程的细致探究。
这种全新的评测机制不仅关注最终输出,还重视内部推理路径,揭示了大型推理模型“思考”的真实情况。大量实验结果表明,当前的LRMs在解决超出一定复杂度阈值的问题时,准确率出现完全崩溃。这一现象令人意外地反映出模型推理努力在问题复杂度初期随之增强,但达到某一临界点后即使在足够的推理预算下推理强度反而减弱。研究比较了等推理计算量下的大型推理模型和标准大型语言模型,发现三种显著不同的性能表现阶段。在低复杂度任务中,标准语言模型的表现令人惊讶地优于LRMs;中等复杂度任务则体现出LRMs利用额外思考带来的优势;而在高复杂度任务中,两类模型均表现出推理能力的全面崩溃。深入分析模型的精确计算能力,研究发现LRMs难以有效执行明确算法,且在不同谜题之间表现不一致,进一步限制了其推理表现。
对推理路径的详细审查揭示了模型探索解空间的模式和计算行为,帮助研究人员更好理解其潜在优势和明显短板。大型推理模型在复杂推理领域虽有突破性的提升,但其固有的限制同样显著。模型难以稳定执行所需的明确算法,且在面对复杂组合问题时表现出不可预测或不连贯的推理策略,凸显出其推理能力仍处于发展阶段。标志性的复杂推理任务如数学题或编程问题,虽然当前模型在表面准确率上呈现改进,但并未真正达到人类水平的深度理解和连贯推理。针对这些挑战,研究人员进一步提出通过强化学习引导语言模型进行“交织推理”训练,即在回答问题的不同阶段智能交替进行思考与回答。这种新颖训练范式通过减少推理链条的冗余,提高了推理的效率和时间响应速度,展现出更贴近实际场景需求的潜力。
尽管如此,人工智能在实质推理能力上的瓶颈依然存在。无论是大型语言模型还是专门的大型推理模型,在处理高复杂度长链推理时都面临能力崩溃的困境,这一发现对未来模型架构设计和训练策略提出了新要求。人工智能领域正在通过更加细致严谨的评测方式,结合可控的逻辑谜题环境,力图解开模型思考背后的迷局。仅以最终正确答案评判推理能力的传统方法已难以满足需求,而对模型内部思考路径的分析成为评估智能水平的关键。研究不仅揭示了大型推理模型的优点,如在一定复杂度范围内推理过程的连贯性和技巧性,也警示了它们在执行明确算法时的脆弱性,这对于未来提升模型准确性和稳定性至关重要。展望未来,理解和克服大型推理模型的推理瓶颈将成为人工智能研究的重要方向。
随着更多创新训练技术的出现,如强化学习指导下的交织推理,以及更加丰富的挑战性测试集,模型的真实推理水平有望进一步提升。与此同时,加强对模型推理过程的可解释性与可控性研究也是必不可少的,这有助于建立可信赖的智能系统,满足日益增长的应用需求。总的来说,大型推理模型“思维幻觉”的揭示,促使学界重新审视人工智能推理的本质和边界。通过融合问题复杂度分析和推理路径剖析,研究为人工智能未来的发展提供了新视角,指引人们在智能系统设计上更加注重内在逻辑与推理机制的构建,而非仅仅追求表面答案的精准。未来,随着更多理论与实验的深入,期待这些模型能够真正实现类似人类的深度推理和创新思考,推动人工智能迈向更高水平的认知智能时代。