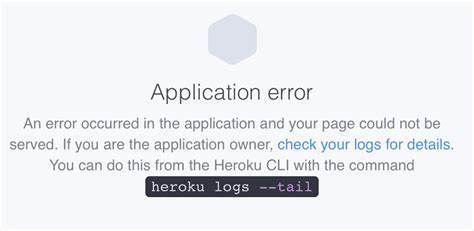
作为全球领先的代码托管平台,GitHub在软件开发社区中的作用不可替代。然而,近期发生的GitHub API故障事件却引发了广大开发者和企业用户的广泛关注。本次服务中断不仅影响了GitHub的GraphQL接口,也波及到了包括问题更新、拉取请求合并以及自动化工作流等多个核心功能。此次事件无疑暴露出大型云服务在高可用性与风险管理上的诸多挑战,同时也提供了一次深刻的反思和学习契机。 首先,要理解GitHub API服务中断的具体表现和范围。报告显示,GitHub的GraphQL端点(https://github.com/_graphql)出现了功能故障,导致开发者无法正常更新Issue。
同时,GitHub的支持系统也遭遇严重的服务器错误,显示多个500状态码,令用户无法通过官方渠道提交和跟踪支持请求。这些问题对依赖GitHub作为开发工作核心平台的团队造成极大不便,尤其是在持续集成与持续部署(CI/CD)流程中,拉取请求的合并和自动化操作被迫中断,影响了软件迭代的速度和质量。 探究此次故障的可能原因,虽然GitHub官方尚未详细公布根本原因,但通过状态页面和社区反馈可以判断,有关Copilot相关服务可能存在依赖问题。GitHub Copilot作为一项基于人工智能的代码提示工具,其服务架构与API的多个关键部分紧密关联,一旦Copilot服务出现异常,可能波及多个相关组件,导致API响应异常。此外,集成的依赖服务之间的耦合度较高,也加大了单点故障向多服务扩散的风险。 服务中断对开发者生态的影响不容小觑。
GitHub作为版本管理和团队协作的核心平台,其稳定性直接关系到项目的进展和质量。API无法正常使用会影响自动化脚本、第三方工具和内部系统的正常运作。例如,持续交付流水线依赖GitHub API触发构建和部署任务,接口中断将使得自动化流程陷入停滞,同时也限制了开发者对代码和问题的管理能力。企业客户更是面临业务交付计划延误、团队沟通成本上升等连锁反应。 应对此次GitHub API中断事件,开发者和企业应强化对平台依赖性的认识,并制定完善的风险应对策略。首先,可以考虑构建多重备选方案,例如使用本地镜像或者其他托管平台作为临时替代,降低单一平台故障带来的冲击。
其次,加强自动化流程的弹性设计,避免严格依赖单一API接口的触发,增加人工干预可能性和异常响应机制。此外,提升开发团队对于故障实时响应的敏感度和协作能力,建立健全的沟通渠道,对于快速定位和解决问题具有积极意义。 从平台提供商角度,GitHub此次事件也敲响了警钟。不断优化服务架构,降低服务间的耦合度,实现更加隔离和高可用的系统设计,是保障服务稳定的重要方向。同时,加强对前沿技术如人工智能辅助开发工具的安全性和稳定性测试,避免因新业务模式带来的潜在风险,是提升平台整体质量不可忽视的一环。 此次GitHub API中断也引发了社区层面的广泛讨论。
开发者们积极分享自己的应对经验和临时解决方案,共同寻求降低受影响范围的切实途径。利用开源社区的力量,快速传播信息和资源,提升整体应对能力,展现了开放协作生态系统的优势和韧性。与此同时,也促使各方关注云服务及平台依赖的深层次问题,呼吁行业加强标准制定和风险防控研究。 总结来看,GitHub API的服务中断,是云服务运营复杂性和技术挑战的集中体现。作为用户,提升风险意识,完善备选方案与应急流程,才能减少类似事件带来的影响。从服务提供者的角度,持续推进技术创新与架构优化,保障稳定性和安全性,是赢得用户信赖的关键。
此次事件为整个开发者社区提供了宝贵的学习机会,推动各方在云服务可靠性方面迈出更坚实的步伐。未来,随着技术不断进步和生态系统日趋完善,期望此类重大中断事件将大幅减少,更好地支持全球软件开发的高速发展和创新需求。