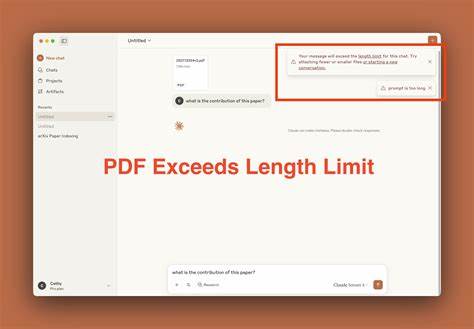
在当今数字化信息爆炸的时代,PDF文档已成为存储和传递重要信息的标准格式。然而,面对数百页甚至上千页的长PDF,传统自然语言处理模型往往难以突破上下文窗口限制,导致无法全面理解文件内容。这对研究人员、律师、学者以及需要处理长文档的各类专业人士来说,是极大的挑战。幸运的是,随着大语言模型(LLM)技术的纵深发展,一种名为PageIndex MCP的新兴解决方案,正在革新人们与超长PDF文档交互的方式。PageIndex MCP完美整合到流行的Cursor和Claude Desktop等LLM应用中,使用户能够跨越传统上下文窗口限制,实现高效、连贯的长文档对话体验。PageIndex MCP的核心价值在于其对长PDF的智能分页索引与上下文检索能力。
这意味着,无论PDF文件多么庞大,系统都能精准拆分内容,动态定位相关页码,并将关键上下文传递给插件支持的大语言模型,确保回答的准确性与连贯性。这种闭环交互方式极大提升了用户对文档的掌控力和信息检索速度。PageIndex MCP倡导两种主要配置方案,满足不同用户的多样化需求。第一种配置方案是通过远程MCP服务器实现快速部署。用户只需添加相应的MCP服务器地址配置,即可无缝接入远程服务,无需繁琐安装步骤,适合希望快速体验和测试功能的用户。第二种方案支持本地PDF上传,利用Node.js环境中本地启动MCP服务器,保护用户隐私安全,同时针对本地文档进行深度处理。
这种模式兼具灵活性与安全性,尤其适合企业级用户或关注数据隐私的专业人士。PageIndex MCP不仅具备卓越的技术优势,还能完美嵌入日常LLM工作流。借助该工具,用户可以在Cursor和Claude Desktop等平台直接与长PDF进行自由对话,无需先行手动摘录或拆分文档内容。这种极简化的工作流程,极大降低了使用门槛,提高了文档查询效率。结合PageIndex MCP的强大检索与索引算法,用户可以通过关键字或语义查询快速定位文件中的相关章节或段落,极大缩减信息查找时间。此外,PageIndex MCP的开放源码和活跃的GitHub社区,确保了其持续优化和功能升级。
用户可以通过官方仓库获取示例代码、配置指南和最佳实践,便于集成和定制开发。而丰富的社区支持和Discord群组,也为遇到问题的用户提供了快捷的技术问答和经验分享平台。随着智能文档处理技术的推广,PageIndex MCP代表了面向未来的长文档交互范式。其核心优势不仅在于绕开当前大型语言模型的上下文窗口限制,还在于构建了一个灵活多元的文档索引生态系统,帮助用户实现智能化知识管理和多模态信息融合。无论是学术研究、法律咨询,还是企业知识库管理,PageIndex MCP和相关聊天接口的结合,带来了前所未有的效率和智能化体验。未来,随着更多支持PageIndex MCP的LLM平台出现,人们对长文档的依赖会更加自然且高效。
文档查询、知识提炼以及复杂问题推理将成为交互式智能助手的常态,显著提升工作及学习的质量和速度。综上所述,PageIndex MCP作为一款面向长PDF交互的创新解决方案,不仅解决了传统大语言模型面临的上下文窗口限制,还为用户带来了便捷、安全的全新使用体验。其与Cursor和Claude Desktop等主流平台的深度融合,标志着智能文档处理迈入了全新篇章。对每一位面对海量文档、追求高效智能驱动的用户来说,深入了解并掌握PageIndex MCP的应用,无疑是开启未来数字办公与研究新纪元的重要钥匙。 。