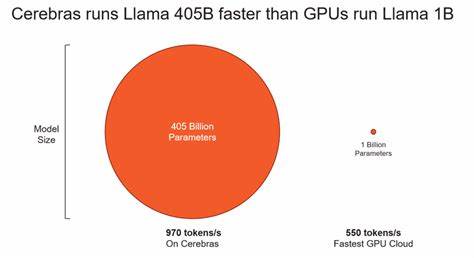
随着人工智能技术的飞速发展,计算能力的提升成为推动行业进步的关键因素。Cerebras作为一家专注于加速AI计算的公司,其发布的超大规模芯片引起了广泛关注。人们常常好奇,Cerebras的产品在实际应用中到底有多快?本文将深入剖析Cerebras的速度优势,揭示其背后的技术创新和实际性能表现。Cerebras的核心竞争力源自其独特的芯片设计——世界上最大的单芯片计算机。这个芯片被誉为“瓦片处理器”,面积超过80000平方毫米,集成了超过4.5万亿个晶体管。相比传统GPU,Cerebras的芯片面积增大了数十倍,这使得其具备更强的并行计算能力和更高的内存带宽。
Cerebras芯片根据其瓦片结构设计,包含了数百万个处理核心,每个核心协同工作,实现极致的并行处理效率。这种设计极大地减少了数据在芯片内部的传输延迟,提高了数据吞吐量,使得AI训练和推理的速度得到显著提升。实际速度表现上,Cerebras在多项AI任务中表现出令人惊叹的成绩。尤其是在大规模神经网络训练中,其速度远超传统GPU集群。由于芯片内存容量巨大且访问速度极快,模型训练过程中数据加载瓶颈大大减少,使得整体训练效率提升显著。此外,Cerebras系统不仅在速度上有优势,功耗方面也表现优异。
高效的芯片架构设计使得其在提供强劲算力的同时,能够保持较低的能耗,降低数据中心的运营成本。Cerebras的系统还配备了先进的软件栈,能够优化任务分配和资源利用。这一系列软件优化和硬件设计的结合,帮助系统充分发挥硬件潜力,实现极速计算。由此可见,Cerebras的速度优势不仅仅是硬件层面的突破,更是软硬件协同优化的结果。这使得其在AI领域的应用范围不断扩大,从自然语言处理到计算机视觉,再到复杂的科学计算模型训练,Cerebras都能带来显著的性能提升。面对日益增长的AI模型规模和计算需求,Cerebras提供了一种新的解决方案,能够满足未来数年内AI发展对算力的挑战。
展望未来,随着芯片设计和制造工艺的不断进步,Cerebras有望继续保持行业领先地位,推动AI计算速度和效率迈上新台阶。综上所述,Cerebras的速度优势体现在其超大规模芯片架构、强大的并行计算能力、低延迟的内存访问以及软硬件的高度协同优化。其超越传统GPU集群的性能,为AI行业的发展提供了坚实的技术保障,开启了AI计算的新纪元。









