随着人工智能和人机交互技术的飞速发展,传统的三维模型操作方式正迎来革新。与鼠标和键盘相比,利用自然的语音指令和手势动作来控制3D模型为用户提供了更加直观、高效且沉浸式的操作体验。开源社区近期出现了一款创新的项目,通过结合语音识别和手势识别技术,实现了对三维模型的精准控制,这种多模态交互方式正在引领3D设计及相关领域的技术革命。 在计算机图形学和虚拟现实领域,3D模型是构建虚拟环境和数字内容的基础。以往,设计师和开发者依赖于复杂的软件界面,通过鼠标点击、键盘输入或手柄操作来对模型进行旋转、缩放、平移等调整。而这些交互方式不仅对新手存在较高的学习门槛,在长时间操作中也容易引发疲劳。
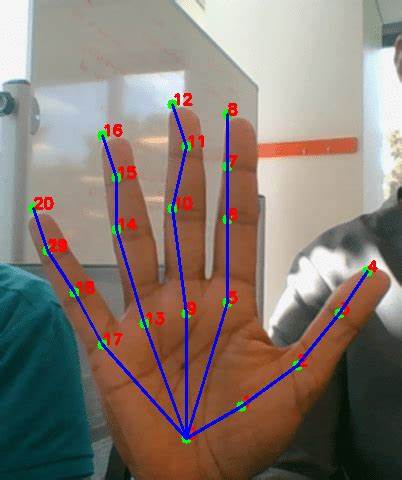
通过语音与手势的结合,用户可以减少物理操作负担,利用更加自然的表达方式完成复杂的功能调用,提高工作效率和体验舒适度。 该开源项目的核心在于整合多种先进技术。语音识别模块基于深度学习模型,能够准确捕捉并识别用户的自然语言指令,包括对3D模型旋转角度、缩放比例、颜色变化等多样性的需求。同时,手势识别通过摄像头捕捉用户手部动作,借助计算机视觉算法实时分析手势类别和轨迹,转换成对应的操作命令。这种双模态融合不仅提升了控制的稳定性,也增强了系统的灵活性,使其适应不同用户的个性化操作习惯。 开源属性对于该项目的快速发展尤为重要。
社区成员持续为系统新增功能,包括对更多手势动作的支持、更丰富的语音指令词库以及跨平台兼容性改进。同时,开源模式促进了技术透明和知识共享,研究人员和开发者能够基于已有框架进行扩展,推动技术不断进步。开发者还发布了详尽的文档和示例代码,降低了新用户的入门门槛,促进了教学、科研以及商业应用的广泛应用。 应用层面,语音与手势控制3D模型技术在多个行业展现出强大潜力。在工业设计领域,设计师可以直接用手势旋转产品原型模型,同时用语音调整参数,使设计流程更为直观快捷。在医疗领域,医生通过语音和手势导航查看三维医学影像,有效避免了传统操作时手部接触不洁净设备的卫生风险。
娱乐和游戏产业同样受益于更丰富的交互方式,提升沉浸感和互动性,增强用户体验。 除了具体应用,技术实现背后的挑战也值得关注。实时处理手势和语音的同步识别对系统性能提出了较高要求,如何减少延迟并兼顾准确率是核心优化方向。多样的环境光线、背景噪声及不同使用者的体态差异,也给算法的稳定性带来考验。为此,项目组引入了自适应算法和多传感器融合技术,以提升系统的鲁棒性和整体交互质量。 未来,随着人工智能、边缘计算和5G通信的进一步发展,多模态交互技术将会愈发成熟且普及。
语音和手势结合不仅限于3D模型控制,更有望拓展到智能家居、自动驾驶、智慧医疗等多个领域,成为人机交互的新常态。同时,虚拟现实(VR)和增强现实(AR)技术的融合将进一步丰富交互体验,使虚拟与现实的边界更加模糊,带来前所未有的沉浸式感受。 总结来看,开源社区的这款语音与手势结合控制3D模型的项目,突破了传统交互方式的限制,开启了人机交互创新的新时代。它不仅为设计、医疗、娱乐等行业带来实用工具,同时也为多模态智能交互技术的推广奠定坚实基础。随着技术不断迭代升级,未来人们将能以更加自由、自然的方式驾驭三维数字空间,极大地促进数字内容的创作与应用发展。掌握并应用这一技术,将成为推动数字化转型和智能交互进步的重要力量。
。