随着云原生技术的快速发展,Kubernetes已成为现代容器编排的核心平台。许多企业和组织使用Kubernetes管理数千甚至数万个节点的集群,以满足大规模计算和服务调度的需求。在如此庞大的规模面前,Kubernetes的控制平面性能成为决定系统稳定性的重要因素,而List API则是其中的“弱点”之一。本文将深入探讨Kubernetes List API的性能与可靠性问题,揭示其面临的挑战,分析版本迭代带来的改进,并分享提升集群稳定性的实用建议。 List API主要用于客户端查询Kubernetes资源列表,例如Pod、服务、自定义资源等操作。在大规模集群环境中,单次查询可能涉及数十万到数百万级别的资源对象,因而调用成本极高。
List请求占用大量API服务器和etcd资源,可能导致CPU负载激增、内存消耗激增甚至服务宕机。当请求没有良好分页和缓存机制时,问题尤为严重。 首先,对List API成本的理解至关重要。性能消耗主要来源于两个方面:etcd查询的键值操作数和API服务器序列化/反序列化响应数据所需的CPU和内存。etcd在存储大量数据时,对于大范围扫描的请求需要遍历众多键值对,导致响应延迟升高。API服务器则需要将存储数据编码为JSON或Protobuf格式返回客户端,而大规模数据序列化过程极其费时且占用大量内存。
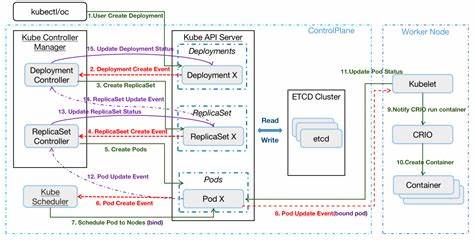
内存不足时,Go语言运行时的垃圾回收机制会频繁触发,进一步消耗CPU资源,形成恶性循环。 针对以上瓶颈,Kubernetes引入了分页(分页查询)机制,通过在List请求中加入limit参数,限制每次返回的资源对象数量,从而降低单次查询压力。分页请求会返回一个继续标记(continue token),客户端可据此异步请求后续资源页。不过需要注意的是,部分组合参数下,如limit与resourceVersion=0的搭配,会导致分页被API服务器忽略,变成一次性的全量查询,造成巨大负载。 大多数Kubernetes控制器通过informers使用List+Watch机制来减少API请求量。基于client-go的控制器默认启用分页,有效防止单次请求引发性能瓶颈。
但用户自行实现或者直接调用API时若未正确分页,极易发生性能问题。此外,若集群版本较旧(早于1.31),List请求不会优先访问API服务器内存中的watch缓存,而是直接访问etcd,结果导致查询延迟剧增。此行为使得基于标签选择器和字段选择器的过滤操作非常低效,因为API服务器必须将整个资源集合从etcd读取后再在内存中进行过滤。 新版本的Kubernetes对watch cache进行了诸多优化。自1.31版本开始,大多数get和list请求都能从watch缓存中读取数据,而不是访问etcd。watch缓存会持续同步etcd数据,并为客户端请求提供近乎实时且一致的视图,极大地降低了etcd压力和API响应延迟。
同时,该机制支持使用标签和字段选择器快速过滤资源,提升查询效率。除了缓存改进,1.33版本引入了更加高效的响应编码机制,避免API服务器因编码海量资源时产生巨大内存波动。该特性实现了分块编码,逐个序列化资源对象,极大降低内存峰值,提升了List请求的稳定性。 Kubernetes还在持续探索新的优化方案。1.34版本计划引入基于watch缓存的分页支持,解决了目前分页跳页仍需访问etcd的弊端,并允许客户端分页请求在内存缓存中高效完成。此外,未来版本将尝试通过让informers实现流式数据传输,替代传统的List+Watch两步操作来降低内存消耗和延迟,使得控制器重启时负载更小,提升系统整体性能。
除了版本升级和底层改进,用户自身的操作策略同样关键。应避免在DaemonSet等节点本地代理程序中大量并发发起针对全集群资源的List请求,因其容易产生成千上万的并发查询,导致API服务器压力骤增。节点本地代理程序更适合使用kubelet本地API进行Pod查询,减轻控制平面负担。严格的RBAC权限管理同样重要,应避免滥用高权限用户进行无节制的List操作。利用API优先级与公平性(APF)功能合理分配请求优先级,防止低优先级请求挤占资源。监控审计日志能及时发现异常的高频List调用,促进运维管理。
在内存管理方面,调整环境变量GOGC(Go垃圾回收调节参数)有助于缓解API服务器因频繁GC导致的CPU飙升,常见调整为200以延迟回收时机,但需结合实际负载反复测试。云托管Kubernetes环境可能不支持该配置,但对自建集群尤为有用。 对于运营者来说,升级集群到1.31及更高版本乃是基础性保障。最新版本的改进消除了早期版本存在的诸多严重性能瓶颈,为大规模集群的高可用提供了技术支撑。同时,应结合集群规模、业务特性合理设计控制器架构,避免集群演变成单点瓶颈。大型企业如LinkedIn、Uber和OpenAI纷纷在官方推荐规模之外运营超大规模集群,积累了许多实践经验。
综上所述,Kubernetes List API在大规模集群运营中是性能和稳定性的重要组成部分。理解其工作机制和潜在风险,结合版本升级和优化策略,有助于防止控制平面因高负载走向崩溃。未来,随着社区持续推动watch缓存分页、流式Watch以及更智能的调度机制,List API的性能瓶颈将得到进一步缓解,推动云原生平台在超大规模计算场景中的广泛应用。持续关注相关更新并及时采取行动,是保障集群稳定与高效运行的关键。